Vector search demo with the arXiv paper dataset, HuggingFace, OpenAI, FastAPI, React, and Redis as the vector database.
https://github.com/RedisVentures/redis-arXiv-search
https://docsearch.redisventures.com/
https://github.com/RedisVentures/redis-arXiv-search
https://docsearch.redisventures.com/
GitHub
GitHub - redis-developer/redis-arXiv-search: Vector search demo with the arXiv paper dataset, RedisVL, HuggingFace, OpenAI, Cohere…
Vector search demo with the arXiv paper dataset, RedisVL, HuggingFace, OpenAI, Cohere, FastAPI, React, and Redis. - redis-developer/redis-arXiv-search
👍2
Forwarded from Machinelearning
New approach deviates from image-text contrastive learning by relying on pre-trained language models to guide the learning rather than minimize a cross-modal similarity.
Новый альтернативный подход к визуальному обучению: с использованием языкового сходства для выборки семантически схожих пар изображений.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
❤2👍2🔥1
Forwarded from Data Science by ODS.ai 🦜
LLaMA: Open and Efficient Foundation Language Models
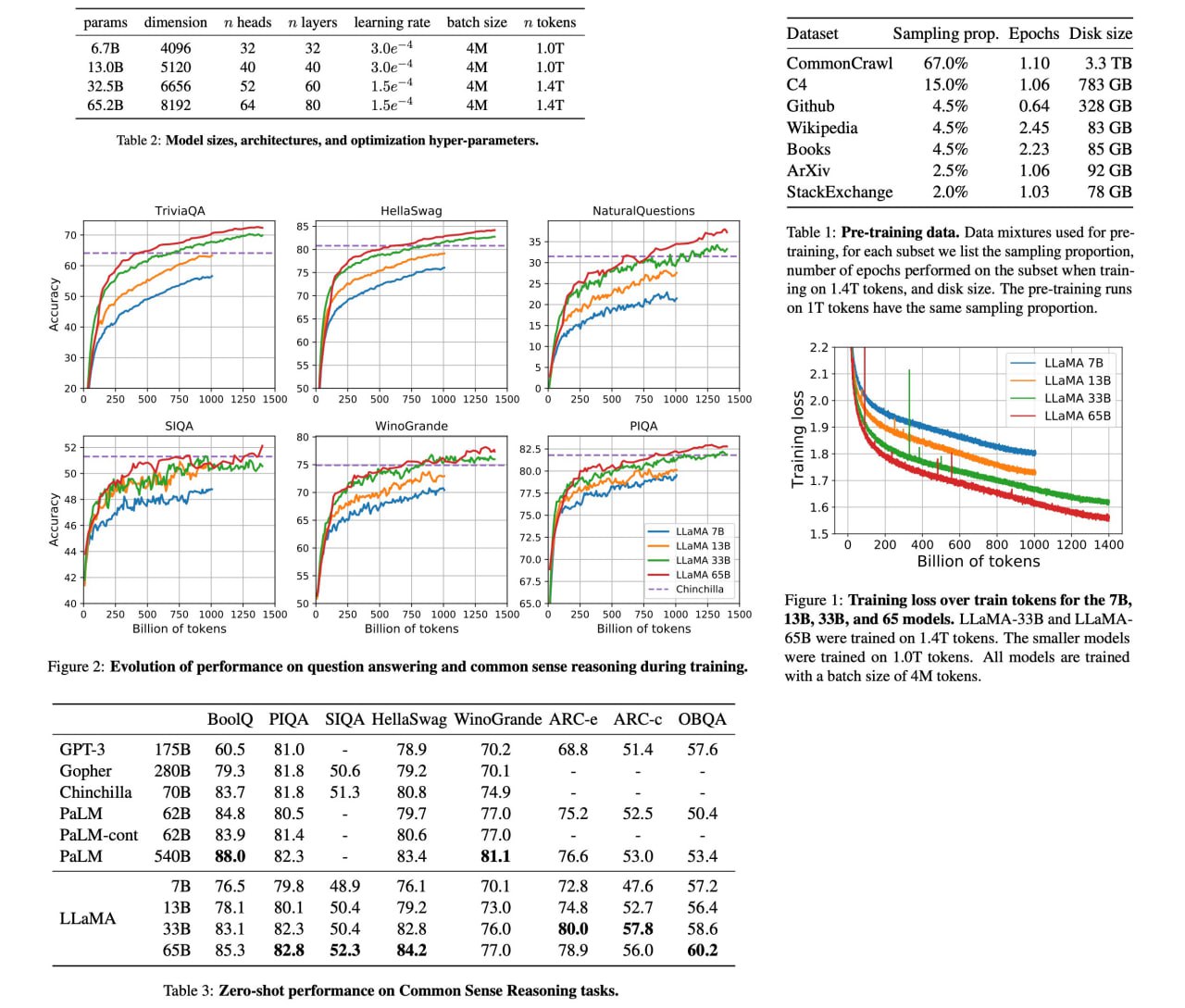
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
❤🔥2👍1
Open source implementation for LLaMA-based ChatGPT training process. Faster and cheaper training than ChatGPT (wip)
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
👍3
xFormers - Toolbox to Accelerate Research on Transformers
xFormers is: Customizable building blocks: Independent/customizable building blocks that can be used without boilerplate code. The components are domain-agnostic and xFormers is used by researchers in vision, NLP and more.
Research first: xFormers contains bleeding-edge components, that are not yet available in mainstream libraries like pytorch.
Built with efficiency in mind: Because speed of iteration matters, components are as fast and memory-efficient as possible. xFormers contains its own CUDA kernels, but dispatches to other libraries when relevant.
https://github.com/facebookresearch/xformers
xFormers is: Customizable building blocks: Independent/customizable building blocks that can be used without boilerplate code. The components are domain-agnostic and xFormers is used by researchers in vision, NLP and more.
Research first: xFormers contains bleeding-edge components, that are not yet available in mainstream libraries like pytorch.
Built with efficiency in mind: Because speed of iteration matters, components are as fast and memory-efficient as possible. xFormers contains its own CUDA kernels, but dispatches to other libraries when relevant.
https://github.com/facebookresearch/xformers
GitHub
GitHub - facebookresearch/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.
Hackable and optimized Transformers building blocks, supporting a composable construction. - facebookresearch/xformers
👍2
Generative Ai pinned «xFormers - Toolbox to Accelerate Research on Transformers xFormers is: Customizable building blocks: Independent/customizable building blocks that can be used without boilerplate code. The components are domain-agnostic and xFormers is used by researchers…»
🤗 Diffusers provides pretrained diffusion models across multiple modalities, such as vision and audio, and serves as a modular toolbox for inference and training of diffusion models.
https://github.com/huggingface/diffusers/tree/main/examples/community#magic-mix
https://github.com/huggingface/diffusers/tree/main/examples/community#magic-mix
Forwarded from Machinelearning
😊 HugNLP
HugNLP is a unified and comprehensive NLP library based on HuggingFace Transformer.
HugNLP — это новая универсальная NLP библиотека основанная на Hugging Face, для повышения удобства и эффективности работы c текстами.
🖥 Github: https://github.com/wjn1996/hugnlp
⏩ Paprer: https://arxiv.org/abs/2302.14286v1
⭐️ Dataset: https://paperswithcode.com/dataset/clue
⏩ HF for complex text classification: https://huggingface.co/blog/classification-use-cases
@ai_machinelearning_big_data
HugNLP is a unified and comprehensive NLP library based on HuggingFace Transformer.
HugNLP — это новая универсальная NLP библиотека основанная на Hugging Face, для повышения удобства и эффективности работы c текстами.
@ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3❤2🔥1
Forwarded from Machinelearning
Ultra fast ControlNet with 🧨 Diffusers
ControlNet provides a minimal interface allowing users to customize the generation process up to a great extent.
Новый пайплайн StableDiffusionControlNetPipeline, в статье показано, как его можно применять для различных задач. Давайте контролировать!
🤗 Hugging face blog: https://huggingface.co/blog/controlnet
🖥 Colab: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb
🖥 Github: https://github.com/lllyasviel/ControlNet
⏩ Paprer: https://arxiv.org/abs/2302.05543
@ai_machinelearning_big_data
ControlNet provides a minimal interface allowing users to customize the generation process up to a great extent.
Новый пайплайн StableDiffusionControlNetPipeline, в статье показано, как его можно применять для различных задач. Давайте контролировать!
🤗 Hugging face blog: https://huggingface.co/blog/controlnet
@ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥3👍2
Forwarded from Hacker News
Visual ChatGPT (🔥 Score: 152+ in 2 hours)
Link: https://readhacker.news/s/5zPu5
Comments: https://readhacker.news/c/5zPu5
Link: https://readhacker.news/s/5zPu5
Comments: https://readhacker.news/c/5zPu5
GitHub
GitHub - chenfei-wu/TaskMatrix
Contribute to chenfei-wu/TaskMatrix development by creating an account on GitHub.
Forwarded from Machinelearning
This media is not supported in your browser
VIEW IN TELEGRAM
StyleGANEX - Official PyTorch Implementation
Encoder that provides the first-layer feature of the extended StyleGAN in addition to the latent style code.
🖥 Github: https://github.com/williamyang1991/styleganex
⏩ Paper: https://arxiv.org/abs/2303.06146v1
⭐️ Colab: http://colab.research.google.com/github/williamyang1991/StyleGANEX/blob/master/inference_playground.ipynb
💨 Project: https://www.mmlab-ntu.com/project/styleganex/
ai_machinelearning_big_data
Encoder that provides the first-layer feature of the extended StyleGAN in addition to the latent style code.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3🔥1
Forwarded from CGIT_Vines (Marvin Heemeyer)
This media is not supported in your browser
VIEW IN TELEGRAM
Вот эта "неидеальность" со временем уйдёт, а мне так даже заходит больше. А ведь раньше гличи были на пике трендов.
Если хотите погонять свою видяху для создания Multi-frame Video rendering for SD, то вам вот за этой тулзовиной.
Если хотите погонять свою видяху для создания Multi-frame Video rendering for SD, то вам вот за этой тулзовиной.
❤🔥2
Forwarded from Denis Sexy IT 🤖
Официальный пресс релиз о GPT 4:
https://openai.com/research/gpt-4
Из интересного, она на вход может принимать картинки, не просто текст 🌚 про параметры я еще не почитал сам
Записаться в API вейтлист можно тоже по ссылке выше.
Кстати, если у вас ChatGPT Plus то вам дадут к ней доступ и так
https://openai.com/research/gpt-4
Из интересного, она на вход может принимать картинки, не просто текст 🌚 про параметры я еще не почитал сам
Записаться в API вейтлист можно тоже по ссылке выше.
Кстати, если у вас ChatGPT Plus то вам дадут к ней доступ и так
GPT-4 Developer Livestream
https://www.youtube.com/watch?v=outcGtbnMuQ
https://www.youtube.com/watch?v=outcGtbnMuQ
YouTube
GPT-4 Developer Livestream
Join Greg Brockman, President and Co-Founder of OpenAI, at 1 pm PT for a developer demo showcasing GPT-4 and some of its capabilities/limitations.
Join the conversation on Discord here: discord.gg/openai. We'll be taking audience input from #gpt4-demo-suggestions.
Join the conversation on Discord here: discord.gg/openai. We'll be taking audience input from #gpt4-demo-suggestions.
Forwarded from эйай ньюз
This media is not supported in your browser
VIEW IN TELEGRAM
ModelScope Text-2-Video: Китайский опенсоурс разродился открытой моделькой для генерации видео по тексту
Это первая диффузионная text2video модель с открытым кодом и опуьликованными весами (1.7 млрд параметров).
Отдельный респект идет Шаттерстоку, данные с которого по всей видимотси использовались для тренировки модели 😂.
Чтобы запустить локально потребуется 16 GB RAM и 16 GB VRAM: инструкция. Пока генерит видео только 256x256.
Ну что, давайте побыстрее заполним интернет проклятыми видео!
Demo
Model weights
@ai_newz
Это первая диффузионная text2video модель с открытым кодом и опуьликованными весами (1.7 млрд параметров).
Отдельный респект идет Шаттерстоку, данные с которого по всей видимотси использовались для тренировки модели 😂.
Чтобы запустить локально потребуется 16 GB RAM и 16 GB VRAM: инструкция. Пока генерит видео только 256x256.
Ну что, давайте побыстрее заполним интернет проклятыми видео!
Demo
Model weights
@ai_newz
👍4