
Forwarded from NeuroMetric
О необычном научном журнале ReScience C
Этот журнал целиком посвящен воспроизведению чужих численных результатов. То есть, берёте опубликованную статью, основанную на компьютерных симуляциях, и пытаетесь независимо воспроизвести оригинальные результаты оттуда. Затем пишете статью, прикладывая ВСЕ свои программы и результаты расчета, о том, получилось ли у вас это сделать.
Огромный двойной плюс такого подхода: проверяется воспроизводимость научных результатов и накапливается опыт количественного анализа чужих статей. Ну и, при добросовестной работе, публикация гарантирована.
Журнал полностью бесплатный (т.н. "платиновый" открытый доступ) - как для читателей, так и для авторов.
Настоятельно рекомендую молодёжи (особенно - аспирантам) публиковать свои "репродукционные" работы в этом журнале.
Сайт журнала: https://rescience.github.io/
PS: ReScience C возник в 2015 году и вызвал заметный интерес, даже завоевал популярность. Поэтому, как иногда водится, люди решили развить/повторить успех и в 2022 году запустили смежный журнал ReScience X, аналогичный по сути, где воспроизводятся не численные симуляции, а настоящие экспериментальные результаты. Но в этом случае, по-видимому, дело продвигается очень туго.
Этот журнал целиком посвящен воспроизведению чужих численных результатов. То есть, берёте опубликованную статью, основанную на компьютерных симуляциях, и пытаетесь независимо воспроизвести оригинальные результаты оттуда. Затем пишете статью, прикладывая ВСЕ свои программы и результаты расчета, о том, получилось ли у вас это сделать.
Огромный двойной плюс такого подхода: проверяется воспроизводимость научных результатов и накапливается опыт количественного анализа чужих статей. Ну и, при добросовестной работе, публикация гарантирована.
Журнал полностью бесплатный (т.н. "платиновый" открытый доступ) - как для читателей, так и для авторов.
Настоятельно рекомендую молодёжи (особенно - аспирантам) публиковать свои "репродукционные" работы в этом журнале.
Сайт журнала: https://rescience.github.io/
PS: ReScience C возник в 2015 году и вызвал заметный интерес, даже завоевал популярность. Поэтому, как иногда водится, люди решили развить/повторить успех и в 2022 году запустили смежный журнал ReScience X, аналогичный по сути, где воспроизводятся не численные симуляции, а настоящие экспериментальные результаты. Но в этом случае, по-видимому, дело продвигается очень туго.
Wikipedia
ReScience C
academic journal publishing replication and reproducibility studies
Forwarded from эйай ньюз
Эндрю Ын вчера выкатил новый мини-курс: How Business Thinkers Can Start Building AI Plugins With Semantic Kernel
Курс длиной всего в 1 час и рассчитан на новичков - технического мяса там не ожидается. Нужно только знать Python.
Но обещают научить строить пайплайны с LLM, пользоваться памятью и писать плагины для решения бизнес-задач. Работа будет идти на базе Semantic Kernel — это SDK для языковых моделей от Microsoft, что-то похожее на уже известный нам LangChain.
Курс ведёт не хер с горы, а VP of Design and Artificial Intelligence из Microsoft.
Ссылка на курс (временно бесплатно)
@ai_newz
Курс длиной всего в 1 час и рассчитан на новичков - технического мяса там не ожидается. Нужно только знать Python.
Но обещают научить строить пайплайны с LLM, пользоваться памятью и писать плагины для решения бизнес-задач. Работа будет идти на базе Semantic Kernel — это SDK для языковых моделей от Microsoft, что-то похожее на уже известный нам LangChain.
Курс ведёт не хер с горы, а VP of Design and Artificial Intelligence из Microsoft.
Ссылка на курс (временно бесплатно)
@ai_newz
www.deeplearning.ai
How Business Thinkers Can Start Building AI Plugins With Semantic Kernel - DeepLearning.AI
Master Microsoft's Semantic Kernel for business applications with LLMs. Enhance planning skills with different AI tools.
Forwarded from ИНХС РАН - Школе
⚡️⚡️ ⚡️ Три факультета МГУ - химический, факультет наук о материалах и факультет фундаментальной физико-химической инженерии запускают новый проект: лекторий для школьников "От химии к материалам".
🧪 Лекторий ориентирован на школьников, осваивающих химию и физику, а также их родителей и учителей. В течение 4 месяцев с сентября по декабрь вас ожидает увлекательное знакомство с тремя основными типами материалов – металлами, керамикой и полимерами. Слушатели познакомятся с тем, как разные материалы работают на благо человека в быту и различных областях техники, спасают и оберегают наше здоровье и создают наше будущее.
⏰ Каждую неделю по средам в 18.00 слушателей ждет встреча с новыми загадками и проблемами, которые решают с помощью материалов.
Лекторий проводится на Электронной образовательной платформе Химического факультета МГУ.
👩💻 Все мероприятия проходят в дистанционном формате, возможно получение сертификата.
Подробности по ссылке:
https://www.chem.msu.ru/rus/from-chemistry-to-materials/
🧪 Лекторий ориентирован на школьников, осваивающих химию и физику, а также их родителей и учителей. В течение 4 месяцев с сентября по декабрь вас ожидает увлекательное знакомство с тремя основными типами материалов – металлами, керамикой и полимерами. Слушатели познакомятся с тем, как разные материалы работают на благо человека в быту и различных областях техники, спасают и оберегают наше здоровье и создают наше будущее.
⏰ Каждую неделю по средам в 18.00 слушателей ждет встреча с новыми загадками и проблемами, которые решают с помощью материалов.
Лекторий проводится на Электронной образовательной платформе Химического факультета МГУ.
👩💻 Все мероприятия проходят в дистанционном формате, возможно получение сертификата.
Подробности по ссылке:
https://www.chem.msu.ru/rus/from-chemistry-to-materials/
Forwarded from Physics.Math.Code
⭕️ Конечная алгебра и ее применения ♾
В серии лекций рассказываются математические понятия и результаты конечной алгебры через призму приложений. Курс включает три лекции:
1. От поиска фальшивых монет к смартфону (Двоичный код Хэмминга и как с помощью кодов исправлять ошибки).
2. Дележ секрета» (определение линейной независимости векторов аксиоматически, теория матроидов)
3. Коды, чтобы запутать, а не исправить («Код тайности» или система МакЭлиса)
Григорий Анатольевич Кабатянский — доктор физико-математических наук, вице-президент по академическому сотрудничеству Сколковского института науки и технологий.
5-7 апреля 2023 г. Майкоп, Адыгейский государственный университет
#алгебра #дискретная_математика #алгоритмы #математика #math #лекции #видеоуроки
💡 Physics.Math.Code
В серии лекций рассказываются математические понятия и результаты конечной алгебры через призму приложений. Курс включает три лекции:
1. От поиска фальшивых монет к смартфону (Двоичный код Хэмминга и как с помощью кодов исправлять ошибки).
2. Дележ секрета» (определение линейной независимости векторов аксиоматически, теория матроидов)
3. Коды, чтобы запутать, а не исправить («Код тайности» или система МакЭлиса)
Григорий Анатольевич Кабатянский — доктор физико-математических наук, вице-президент по академическому сотрудничеству Сколковского института науки и технологий.
5-7 апреля 2023 г. Майкоп, Адыгейский государственный университет
#алгебра #дискретная_математика #алгоритмы #математика #math #лекции #видеоуроки
💡 Physics.Math.Code
Forwarded from СФУ
#библиотека
Стартует набор на программу «Основы научного мастерства»
Мы знаем, вы этого хотите😉
Хотите, чтобы лучшие преподаватели #ИНО научили вас писать красивые, выверенные и мега крутые научные тексты о ваших исследованиях.
Уже сейчас можно пройти регистрацию (под постом👇) на дистанционный (и абсолютно бесплатный) обучающий курс «Основы научного мастерства».
📌К участию приглашаются бакалавры 3-4 курсов, магистранты, аспиранты, молодые учёные, представители студенческих научных сообществ.
🤫Участники курса узнают, как создаются и готовятся к публикации научные тексты; научатся эффективной коммуникации в научном сообществе, освоят принципы коммерциализации результатов интеллектуальной деятельности и смогут выстроить индивидуальную траекторию своего научного развития.
Организатор – Научная библиотека СФУ.
Начало курса: 2 октября
✔️Все участники получат сертификат о повышении квалификации установленного образца.
Стартует набор на программу «Основы научного мастерства»
Мы знаем, вы этого хотите😉
Хотите, чтобы лучшие преподаватели #ИНО научили вас писать красивые, выверенные и мега крутые научные тексты о ваших исследованиях.
Уже сейчас можно пройти регистрацию (под постом👇) на дистанционный (и абсолютно бесплатный) обучающий курс «Основы научного мастерства».
📌К участию приглашаются бакалавры 3-4 курсов, магистранты, аспиранты, молодые учёные, представители студенческих научных сообществ.
🤫Участники курса узнают, как создаются и готовятся к публикации научные тексты; научатся эффективной коммуникации в научном сообществе, освоят принципы коммерциализации результатов интеллектуальной деятельности и смогут выстроить индивидуальную траекторию своего научного развития.
Организатор – Научная библиотека СФУ.
Начало курса: 2 октября
✔️Все участники получат сертификат о повышении квалификации установленного образца.
{kind=link}
Forwarded from gonzo-обзоры ML статей
Mortal Computers
А теперь шутки в сторону и поговорим про фронтир, но не такой как обычно.
Я долго откладывал чтение статьи Джеффри Хинтона про алгоритм обучения Forward-Forward, или FF, (https://arxiv.org/abs/2212.13345). Если вкратце, то это альтернатива бэкпропу, где делается два контрастных форвардпропа, один с позитивными данными, на которых модификацией весов надо максимизировать goodness, другой с негативными, где goodness надо уменьшить. Goodness может определяться по-разному, например, это может быть сумма квадратов активаций.
Этот алгоритм хорош тем, что он локальный, не требует бэкпропа через всю систему, и что особенно важно, может работать с чёрными ящиками, не требуя полного понимания вычислений (и соответственно не имея возможности посчитать от них производную (хотя конечно её можно было бы оценить, но вычислительно это тяжёлая история, особенно для больших сетей)).
По дизайну FF имеет много отсылок к разным вещам типа RBM, GAN, контрастному обучению типа SimCLR/BYOL (оба разбирали в канале), к Хинтоновскому же GLOM. Он более-менее работает на малых сетях и примерах типа MNIST и CIFAR10, на больших это скорее TBD. Возможно, по этому алгоритму и его развитиям мы пройдёмся как-нибудь отдельно (но это не точно), но чтобы не ждать, можете посмотреть кейноут самого Хинтона (https://www.youtube.com/watch?v=_5W5BvKe_6Y) или его рассказ в Eye on AI (https://www.youtube.com/watch?v=NWqy_b1OvwQ), если неохота читать статью.
Так вот, возвращаясь к статье, самая интересная часть там не про алгоритм как таковой. Самое интересное — это пара маленьких разделов в конце про аналоговое железо и mortal computation. В этой теме слилось воедино множество направлений, которыми занимался Хинтон в последние годы, и она важнее, чем FF. Честно говоря, я даже сомневаюсь, что он продолжит работу над FF (хотя там большой раздел про Future Work, и он тоже важный), потому что то, что открылось и кристаллизовалось в итоге, важнее.
Про что речь.
Классические вычисления и computer science построены на том, что компьютеры сделаны для надёжного и точного выполнения инструкций. Благодаря этому, нам не надо заботиться о физическом уровне и об электротехнике; благодаря этому мы можем довольно спокойно отделить железо от софта и изучать последний; благодаря этому программа переносима и потенциально бессмертна -- со смертью железа она не умирает и может быть запущена где-то ещё (ну если админ бэкапы делал и проверял, конечно).
Эта точность и надёжность вычислений даётся довольно дорогой ценой: нужны мощные (по сравнению с нейронами) транзисторы, нужно цифровое кодирование сигналов, нужны алгоритмы для обработки этих сигналов. То же перемножение двух n-битных чисел -- это O(n^2) операций с битами, в то время как в физической системе это можно было бы посчитать параллельно для произвольного количества активаций и весов, если первые задать напряжением, а вторые проводимостью, их произведение даст заряд, который автоматом просуммируется. Даже если устройства не супер быстрые, за счёт такого параллелизма можно быть очень крутым.
Сложность с аналоговыми вычислениями в том, что они очень зависят от конкретных элементов со всеми их несовершенствами, и их точные свойства неизвестны (бэкпроп через неизвестную функцию тоже так себе делать, нужна точная модель форвард пасса). Зато если бы был алгоритм обучения не требующий бэкпропа (а мы знаем, что он есть, на примере мозга), то можно было бы выращивать “железо” даже с неизвестными параметрами и связями, и как бонус иметь устройства с очень низким энергопотреблением. И вместо прецизионного изготовления железа в 2D (ну ок, немного уже в 3D умеем) на заводах стоимостью в пиллиарды долларов, можно было бы дёшево выращивать железо в 3D.
Как антибонус -- устройства становятся смертными, программа теперь неотделима от железа, по крайней мере просто. Недостаточно сделать копию весов, надо как-то обучать (но не бэкпропом). Заранее продолжая аналогию, копию сознания сделать будет проблематично.
А теперь шутки в сторону и поговорим про фронтир, но не такой как обычно.
Я долго откладывал чтение статьи Джеффри Хинтона про алгоритм обучения Forward-Forward, или FF, (https://arxiv.org/abs/2212.13345). Если вкратце, то это альтернатива бэкпропу, где делается два контрастных форвардпропа, один с позитивными данными, на которых модификацией весов надо максимизировать goodness, другой с негативными, где goodness надо уменьшить. Goodness может определяться по-разному, например, это может быть сумма квадратов активаций.
Этот алгоритм хорош тем, что он локальный, не требует бэкпропа через всю систему, и что особенно важно, может работать с чёрными ящиками, не требуя полного понимания вычислений (и соответственно не имея возможности посчитать от них производную (хотя конечно её можно было бы оценить, но вычислительно это тяжёлая история, особенно для больших сетей)).
По дизайну FF имеет много отсылок к разным вещам типа RBM, GAN, контрастному обучению типа SimCLR/BYOL (оба разбирали в канале), к Хинтоновскому же GLOM. Он более-менее работает на малых сетях и примерах типа MNIST и CIFAR10, на больших это скорее TBD. Возможно, по этому алгоритму и его развитиям мы пройдёмся как-нибудь отдельно (но это не точно), но чтобы не ждать, можете посмотреть кейноут самого Хинтона (https://www.youtube.com/watch?v=_5W5BvKe_6Y) или его рассказ в Eye on AI (https://www.youtube.com/watch?v=NWqy_b1OvwQ), если неохота читать статью.
Так вот, возвращаясь к статье, самая интересная часть там не про алгоритм как таковой. Самое интересное — это пара маленьких разделов в конце про аналоговое железо и mortal computation. В этой теме слилось воедино множество направлений, которыми занимался Хинтон в последние годы, и она важнее, чем FF. Честно говоря, я даже сомневаюсь, что он продолжит работу над FF (хотя там большой раздел про Future Work, и он тоже важный), потому что то, что открылось и кристаллизовалось в итоге, важнее.
Про что речь.
Классические вычисления и computer science построены на том, что компьютеры сделаны для надёжного и точного выполнения инструкций. Благодаря этому, нам не надо заботиться о физическом уровне и об электротехнике; благодаря этому мы можем довольно спокойно отделить железо от софта и изучать последний; благодаря этому программа переносима и потенциально бессмертна -- со смертью железа она не умирает и может быть запущена где-то ещё (ну если админ бэкапы делал и проверял, конечно).
Эта точность и надёжность вычислений даётся довольно дорогой ценой: нужны мощные (по сравнению с нейронами) транзисторы, нужно цифровое кодирование сигналов, нужны алгоритмы для обработки этих сигналов. То же перемножение двух n-битных чисел -- это O(n^2) операций с битами, в то время как в физической системе это можно было бы посчитать параллельно для произвольного количества активаций и весов, если первые задать напряжением, а вторые проводимостью, их произведение даст заряд, который автоматом просуммируется. Даже если устройства не супер быстрые, за счёт такого параллелизма можно быть очень крутым.
Сложность с аналоговыми вычислениями в том, что они очень зависят от конкретных элементов со всеми их несовершенствами, и их точные свойства неизвестны (бэкпроп через неизвестную функцию тоже так себе делать, нужна точная модель форвард пасса). Зато если бы был алгоритм обучения не требующий бэкпропа (а мы знаем, что он есть, на примере мозга), то можно было бы выращивать “железо” даже с неизвестными параметрами и связями, и как бонус иметь устройства с очень низким энергопотреблением. И вместо прецизионного изготовления железа в 2D (ну ок, немного уже в 3D умеем) на заводах стоимостью в пиллиарды долларов, можно было бы дёшево выращивать железо в 3D.
Как антибонус -- устройства становятся смертными, программа теперь неотделима от железа, по крайней мере просто. Недостаточно сделать копию весов, надо как-то обучать (но не бэкпропом). Заранее продолжая аналогию, копию сознания сделать будет проблематично.
YouTube
MoroccoAI Conference 2022 Honorary Keynote Prof. Geoffrey Hinton - The Forward-Forward Algorithm
In this Honorary Keynote, Prof. Geoffrey Hinton, Full Professor at University of Toronto, discusses "Learning Deep Neural Networks without Propagating Derivatives".
This is a new learning algorithm for artificial neural networks, called Forward-Forward…
This is a new learning algorithm for artificial neural networks, called Forward-Forward…
Forwarded from Голубь Скиннера
Искусственный интеллект – Пифия современности
#ai
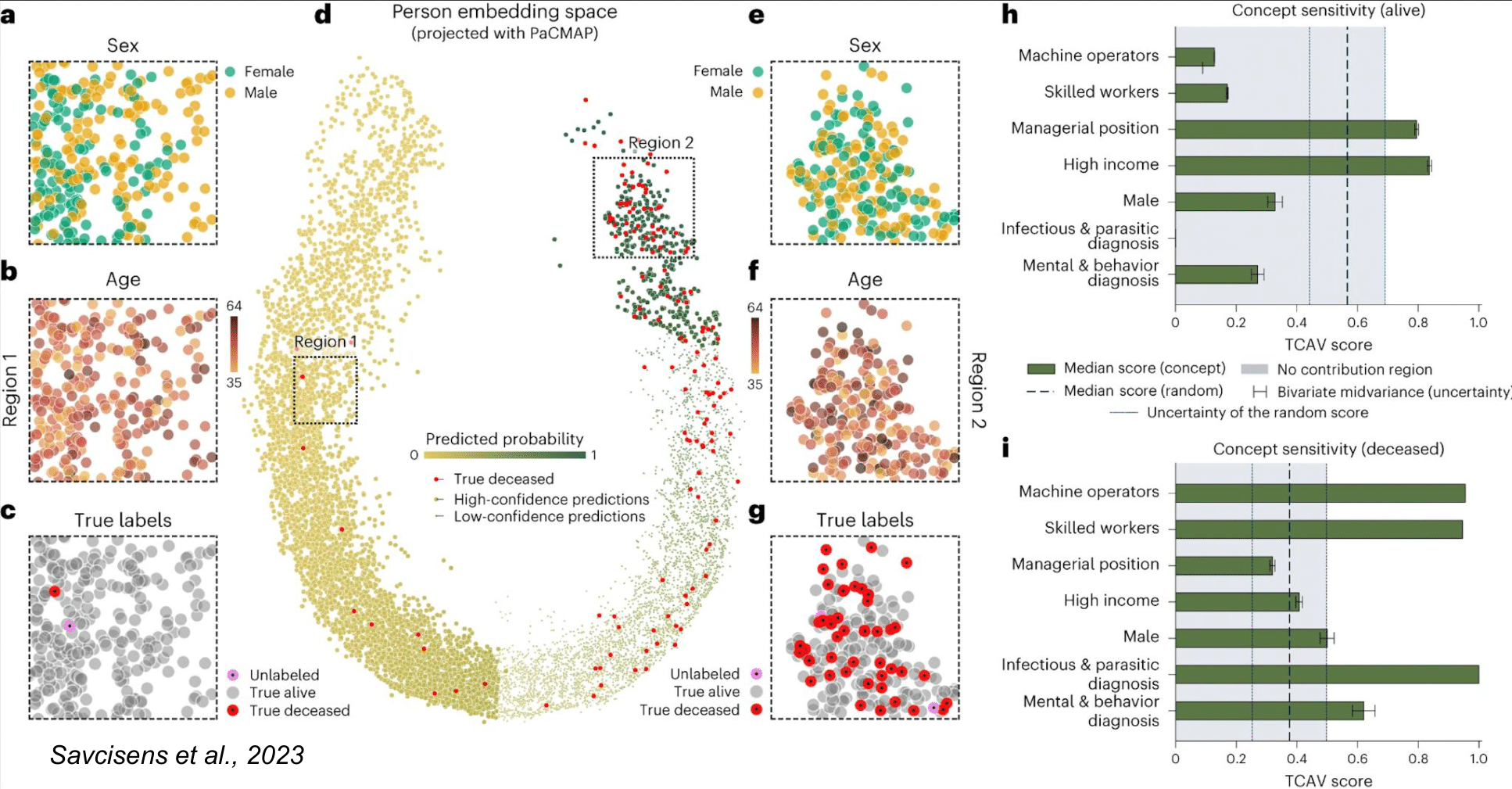
Публикация: Savcisens, G., Eliassi-Rad, T., Hansen, L. K., Mortensen, L. H., Lilleholt, L., Rogers, A., ... & Lehmann, S. (2023). Using sequences of life-events to predict human lives. Nature Computational Science, 1-14.
На пятый день после наступления нового года, когда беспечность настоящего постепенно угасает, неизбежно задумываешься о будущем... В долгосрочной перспективе оно кажется неосязаемым и туманным – по крайней мере, для нас. Но не для искусственного интеллекта!
Недавно в Nature Computational Science была представлена модель life2vec, предсказывающая жизнь людей. Модель опиралась на данные жителей Дании от 25 до 70 лет с 2008 по 2016 года. Эти данные представляли собой детализированную последовательность событий в сферах труда и здоровья: получение зарплаты или стипендии, устройство на работу, посещение врачей, постановку диагнозов и т. д. Используя эти данные, расположенные в хронологическом порядке, модель оценивала каждое событие как изолированно, так и в контексте всей последовательности жизни человека целиком. Это и позволяло осуществить предсказание на ближайшие четыре года.
С технической точки зрения важно подчеркнуть, что в модели не использовались традиционные методы предсказания временных рядов, поскольку события жизни человека характеризуются многомерными признаками и не регистрируются через равные промежутки времени. Наконец, само понятие времени в данном случае усложняется, так как представлено и датой события, и возрастом конкретного человека. С учётом всех сложностей была использована архитектура трансформера. Все категории событий жизни человека составили синтетический "вокабуляр", и последовательность событий жизни рассматривались как "предложения", состоящие из элементов этого вокабуляра. Если упрощать, то задача предсказания следующих событий жизни человека сводилась к задаче предсказания следующих "слов" по аналогии с тем, как это делают ИИ-чатботы.
Что именно может предсказывать модель? Концептуально ограничений нет, поскольку для каждого типа предсказаний на основе сырых данных формируется новое пространство векторов, специфичных для этого типа. То есть каждое событие жизни может быть по-разному представлено в контексте типа предсказания. Это и делает модель в чём-то универсальной. С её помощью удалось предсказать как раннюю смертность для выборки людей от 35 до 65 лет, так и психологически тонкие показатели, связанные с десятью личностными характеристиками экстраверсии. Интересно, что life2vec превзошла модели (рекуррентные нейронные сети), натренированные на данных, относящихся исключительно к предсказываемой переменной.
Представляет интерес пример (см. Рис.) двумерной проекции жизней людей для случая с предсказанием смертности. Выделенные на изображении (d) регионы 1 и 2 соответствуют высокой вероятности выживания и смерти соответственно. Примечательно, что в немалая часть региона 2 представлена молодыми людьми (f), которые в действительности умерли (см. красные точки), что указывает на сложный характер предсказаний, с которыми справилась модель. Реальные смерти, близкие к региону 1 (высокая вероятность выживания) и соответствующие ложно-отрицательному результату, объяснялись несчастными случаями, возникновениями новообразований или инфарктом, что действительно сложнее предсказать на основе имеющихся данных.
Из ограничений модели следует отметить использование лишь небольшого промежутка времени длиной в 8 лет, а также возможные социодемографические искажения, связанные с отсутствием данных тех, кто не получает зарплату или не посещает медицинские учреждения. Впрочем, ничто не мешает в дальнейшем использовать и иные источники данных – например, социальные сети.
Этические сомнения также возникают, но они настолько очевидны, что не требуют пояснений.
P. S. Отдельная благодарность подписчице канала Алине за наводку на статью. И для заинтересованных – по этой ссылке можно найти репозиторий с исходным кодом.
#ai
Публикация: Savcisens, G., Eliassi-Rad, T., Hansen, L. K., Mortensen, L. H., Lilleholt, L., Rogers, A., ... & Lehmann, S. (2023). Using sequences of life-events to predict human lives. Nature Computational Science, 1-14.
На пятый день после наступления нового года, когда беспечность настоящего постепенно угасает, неизбежно задумываешься о будущем... В долгосрочной перспективе оно кажется неосязаемым и туманным – по крайней мере, для нас. Но не для искусственного интеллекта!
Недавно в Nature Computational Science была представлена модель life2vec, предсказывающая жизнь людей. Модель опиралась на данные жителей Дании от 25 до 70 лет с 2008 по 2016 года. Эти данные представляли собой детализированную последовательность событий в сферах труда и здоровья: получение зарплаты или стипендии, устройство на работу, посещение врачей, постановку диагнозов и т. д. Используя эти данные, расположенные в хронологическом порядке, модель оценивала каждое событие как изолированно, так и в контексте всей последовательности жизни человека целиком. Это и позволяло осуществить предсказание на ближайшие четыре года.
С технической точки зрения важно подчеркнуть, что в модели не использовались традиционные методы предсказания временных рядов, поскольку события жизни человека характеризуются многомерными признаками и не регистрируются через равные промежутки времени. Наконец, само понятие времени в данном случае усложняется, так как представлено и датой события, и возрастом конкретного человека. С учётом всех сложностей была использована архитектура трансформера. Все категории событий жизни человека составили синтетический "вокабуляр", и последовательность событий жизни рассматривались как "предложения", состоящие из элементов этого вокабуляра. Если упрощать, то задача предсказания следующих событий жизни человека сводилась к задаче предсказания следующих "слов" по аналогии с тем, как это делают ИИ-чатботы.
Что именно может предсказывать модель? Концептуально ограничений нет, поскольку для каждого типа предсказаний на основе сырых данных формируется новое пространство векторов, специфичных для этого типа. То есть каждое событие жизни может быть по-разному представлено в контексте типа предсказания. Это и делает модель в чём-то универсальной. С её помощью удалось предсказать как раннюю смертность для выборки людей от 35 до 65 лет, так и психологически тонкие показатели, связанные с десятью личностными характеристиками экстраверсии. Интересно, что life2vec превзошла модели (рекуррентные нейронные сети), натренированные на данных, относящихся исключительно к предсказываемой переменной.
Представляет интерес пример (см. Рис.) двумерной проекции жизней людей для случая с предсказанием смертности. Выделенные на изображении (d) регионы 1 и 2 соответствуют высокой вероятности выживания и смерти соответственно. Примечательно, что в немалая часть региона 2 представлена молодыми людьми (f), которые в действительности умерли (см. красные точки), что указывает на сложный характер предсказаний, с которыми справилась модель. Реальные смерти, близкие к региону 1 (высокая вероятность выживания) и соответствующие ложно-отрицательному результату, объяснялись несчастными случаями, возникновениями новообразований или инфарктом, что действительно сложнее предсказать на основе имеющихся данных.
Из ограничений модели следует отметить использование лишь небольшого промежутка времени длиной в 8 лет, а также возможные социодемографические искажения, связанные с отсутствием данных тех, кто не получает зарплату или не посещает медицинские учреждения. Впрочем, ничто не мешает в дальнейшем использовать и иные источники данных – например, социальные сети.
Этические сомнения также возникают, но они настолько очевидны, что не требуют пояснений.
P. S. Отдельная благодарность подписчице канала Алине за наводку на статью. И для заинтересованных – по этой ссылке можно найти репозиторий с исходным кодом.
{kind=link}
Forwarded from ИОХ РАН
«Долина смерти» малотоннажной и микротоннажной химии
🧪Химический синтез — не просто процесс создания новых соединений, это основа для развития технологий и материалов, которые формируют наш мир.
🔹Масштабы производства варьируются от миллиграммового синтеза, где ученые в лабораториях получают вещества для исследований, до крупнотоннажного производства, где производятся основные химические вещества, такие как удобрения и пластик, необходимые в больших количествах для глобального потребления.
🏛 В опубликованной коллективом автором из ИОХ РАН, МГУ и ИНХС РАН статье освещается критический этап масштабирования химического производства, где проекты сталкиваются с проблемами финансирования, информационного дефицита и нехватки специалистов, затрудняющих переход от лабораторного к производственному масштабу.
📑Статья опубликована в журнале «Химический эксперт».
🔗Подробнее — на сайте.
🧪Химический синтез — не просто процесс создания новых соединений, это основа для развития технологий и материалов, которые формируют наш мир.
🔹Масштабы производства варьируются от миллиграммового синтеза, где ученые в лабораториях получают вещества для исследований, до крупнотоннажного производства, где производятся основные химические вещества, такие как удобрения и пластик, необходимые в больших количествах для глобального потребления.
📑Статья опубликована в журнале «Химический эксперт».
🔗Подробнее — на сайте.
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from AIRI Institute
Открыт прием заявок на Лето с AIRI!⚡️
В этом году мы запускаем Школу совместно с Передовой Инженерной Школой ИТМО. Программа пройдет в Санкт-Петербурге с 20 по 30 августа.
🗓 Подать заявку можно по ссылке до 23:59 14 июля 2024 года.
Школа включает в себя лекции, семинары и практическую работу по направлениям:
— Мультимодальные архитектуры и генеративный ИИ в промышленности
— Модели воплощенного ИИ и обучение с подкреплением в робототехнике
— Искусственный интеллект и химия
— Доверенный искусственный интеллект
📍Питание, обучение и проживание бесплатное, оплатить самим нужно будет только проезд.
Подавайте заявки и делитесь постом с друзьями и коллегами!
В этом году мы запускаем Школу совместно с Передовой Инженерной Школой ИТМО. Программа пройдет в Санкт-Петербурге с 20 по 30 августа.
🗓 Подать заявку можно по ссылке до 23:59 14 июля 2024 года.
Школа включает в себя лекции, семинары и практическую работу по направлениям:
— Мультимодальные архитектуры и генеративный ИИ в промышленности
— Модели воплощенного ИИ и обучение с подкреплением в робототехнике
— Искусственный интеллект и химия
— Доверенный искусственный интеллект
📍Питание, обучение и проживание бесплатное, оплатить самим нужно будет только проезд.
Подавайте заявки и делитесь постом с друзьями и коллегами!
Forwarded from Все о блокчейн/мозге/space/WEB 3.0 в России и мире
Media is too big
VIEW IN TELEGRAM
⚡️❗️Game changer ИИ-агенты общаются между собой - Moshi и ChatGPT обсуждают видеоигры
Помните, совсем недавно мы писали о прогнозе основателя #Zoom , который сказал, у каждого будут ИИ-агенты/аватары, которые общаются с другими ИИ-аватарами/агентами.
Сегодня это уже реальность. Представьте, теперь вы можете отправить на встречу своего ИИ-агента вместо себя, раньше на какие-то мероприятия отправлялись адвокаты/юристы, а теперь, когда мир движется к сверхинтеллекту, люди будут иметь как минимум одного ИИ-агента по всем вопросам, и он не будет стоить дорого.
В феврале наш канал прогнозировал, что ИИ-агенты станут одной из основных тем 2024г. Почему? Читайте здесь.
А тут свежий отчет венчурного фонда #a16Z о тренде на голосовые ИИ-агенты.
Помните, совсем недавно мы писали о прогнозе основателя #Zoom , который сказал, у каждого будут ИИ-агенты/аватары, которые общаются с другими ИИ-аватарами/агентами.
Сегодня это уже реальность. Представьте, теперь вы можете отправить на встречу своего ИИ-агента вместо себя, раньше на какие-то мероприятия отправлялись адвокаты/юристы, а теперь, когда мир движется к сверхинтеллекту, люди будут иметь как минимум одного ИИ-агента по всем вопросам, и он не будет стоить дорого.
В феврале наш канал прогнозировал, что ИИ-агенты станут одной из основных тем 2024г. Почему? Читайте здесь.
А тут свежий отчет венчурного фонда #a16Z о тренде на голосовые ИИ-агенты.
Forwarded from Яндекс Образование
Держите, это вам! Большой гайд по промтингу, который помогает эффективно работать с ИИ-инструментами и применять нейросети в учёбе.
🔵 Он научит писать более точные запросы к GPT, чтобы получать качественные ответы
🔵 Поможет оценить, какую работу можно поручить нейросетям, а какую лучше сделать самостоятельно
🔵 И объяснит, как критически оценивать то, что предлагает модель
Все материалы — а ещё практические задания, чтобы закрепить новые #навыки — готовили эксперты Яндекс Образования и факультета компьютерных наук ВШЭ.
Получился целый хэндбук из пяти глав — читайте сами и закидывайте в учебные чаты.
Все материалы — а ещё практические задания, чтобы закрепить новые #навыки — готовили эксперты Яндекс Образования и факультета компьютерных наук ВШЭ.
Получился целый хэндбук из пяти глав — читайте сами и закидывайте в учебные чаты.
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Baseline
Растим смену
🔄 Командой Baseline с Алсу Гимаевой провели курс по управлению проектами студентам УГНТУ. Ребята получили навыки календарно-сетевого планирования, узнали об инструментах BI-аналитики.
После вуза ждем их в рядах планеров 😎
Если хотите укрепить свои харды в BI,↖️ велком к нам на обучение. 🟡 Уже скоро стартует первый поток.
Ставьте реакции, если интересно 🔥 Продолжим обучать до уровня «профи».
После вуза ждем их в рядах планеров 😎
Если хотите укрепить свои харды в BI,
Ставьте реакции, если интересно 🔥 Продолжим обучать до уровня «профи».
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Финансович
⚡️ Google выпустил «убийцу» o1 от OpenAI — пока Альтман показывает ChatGPT в WhatsApp, Гугл выпускает серьёзные вещи.
Работает также: модель ДУМАЕТ перед тем, как ответить — благодаря мозговому штурму ИИ лучше кодит и решает задачки по математике.
И главный нож в спину OpenAI: моделька от Google БЕСПЛАТНАЯ — подрубите VPN, зайдите на AIStudio и выберите справа модель Gemini 2.0 Flash Thinking.
Работает также: модель ДУМАЕТ перед тем, как ответить — благодаря мозговому штурму ИИ лучше кодит и решает задачки по математике.
И главный нож в спину OpenAI: моделька от Google БЕСПЛАТНАЯ — подрубите VPN, зайдите на AIStudio и выберите справа модель Gemini 2.0 Flash Thinking.
Forwarded from Яндекс Образование
Могут ли сервисы сделать образование доступным и персонализированным? Да, и в карточках мы рассказываем об этом на примере нашего ИИ-помощника по математике.
Кстати, ИИ-помощник стал одной из тем YaC 2024 — ищите его в серии «Люди».
Кстати, ИИ-помощник стал одной из тем YaC 2024 — ищите его в серии «Люди».
Forwarded from Innovation & Research
Google выпустил базовый документ, посвященный AI-агентам
Под агентами в нём понимаются программы, которые расширяют возможности генеративных AI-моделей, позволяя им использовать инструменты для доступа к актуальной информации и выполнения действий во внешнем мире. Агент может включать одну или несколько языковых моделей, которые принимают решения о том, как реагировать на запросы пользователей и управлять своими действиями, опираясь на данные, полученные от внешних инструментов.
Ключевыми аспектами агентного подхода являются:
1. Автономность: агенты способны действовать независимо, часто без прямого вмешательства человека, особенно если они снабжены четкими целями или задачами.
2. Целеполагание: агенты имеют конкретные цели, которых они стремятся достичь, используя свои встроенные инструменты и возможность вести рассуждения.
3. Рассуждение и планирование: агенты используют различные методы рассуждений для анализа ситуации и планирования своих дальнейших шагов.
4. Доступ к инструментам: агенты оснащены инструментами, которые позволяют им взаимодействовать с внешним миром, включая выполнение API-запросов, работу с данными и другие операции, которые модель не могла бы выполнить самостоятельно.
То есть, агенты представляют собой мощное сочетание модели, методов рассуждений и инструментов, которое позволяет действовать более эффективно и гибко в реальных условиях.
Ключевым способом реализации агентов разработчики видят схему «когнитивных архитектур». Её ключевые моменты:
1. Агенты расширяют возможности языковых моделей, используя инструменты для доступа к актуальной информации и выполнения сложных задач автономно. В своей работе они могут использовать одну или несколько LLM для принятия решений о том, как перейти через состояния и использовать внешние инструменты для решения различных задач, которые было бы сложно или невозможно решить с помощью одной модели.
2. Основой работы агента является слой оркестрации — когнитивная архитектура, которая структурирует процессы рассуждения, планирования, принятия решений и направляет действия агента. Различные методы рассуждений, такие как ReAct, Chain-of-Thought и Tree-of-Thoughts, предоставляют структуру для слоя оркестрации, который собирает информацию, обрабатывает ее, генерирует ответы или стимулирует действия.
3. Инструменты — расширения, функции и хранилища данных — служат «ключами» к внешнему миру для агентов, позволяя им взаимодействовать с внешними системами и получать доступ к знаниям за пределами обучающих данных. Расширения соединяют агентов с внешними API для получения актуальной информации. Функции дают разработчикам более детальный контроль над потоком данных и выполнением операций. Хранилища данных открывают доступ к структурированным или неструктурированным данным, поддерживая приложения, основанные на извлечении знаний.
Ожидается, что в будущем агенты покажут значительные достижения благодаря усовершенствованию инструментов и возможностей вести рассуждения. Это позволит им решать все более сложные задачи.
Кроме того, стратегический подход «цепочки агентов», объединяющий специализированных агентов для конкретных задач, будет способствовать созданию комплексных систем, работающих наподобие конвейера, каждое звено которого выполняет свою функцию.
#news #AI #бигтехи #политика
https://www.kaggle.com/whitepaper-agents
Под агентами в нём понимаются программы, которые расширяют возможности генеративных AI-моделей, позволяя им использовать инструменты для доступа к актуальной информации и выполнения действий во внешнем мире. Агент может включать одну или несколько языковых моделей, которые принимают решения о том, как реагировать на запросы пользователей и управлять своими действиями, опираясь на данные, полученные от внешних инструментов.
Ключевыми аспектами агентного подхода являются:
1. Автономность: агенты способны действовать независимо, часто без прямого вмешательства человека, особенно если они снабжены четкими целями или задачами.
2. Целеполагание: агенты имеют конкретные цели, которых они стремятся достичь, используя свои встроенные инструменты и возможность вести рассуждения.
3. Рассуждение и планирование: агенты используют различные методы рассуждений для анализа ситуации и планирования своих дальнейших шагов.
4. Доступ к инструментам: агенты оснащены инструментами, которые позволяют им взаимодействовать с внешним миром, включая выполнение API-запросов, работу с данными и другие операции, которые модель не могла бы выполнить самостоятельно.
То есть, агенты представляют собой мощное сочетание модели, методов рассуждений и инструментов, которое позволяет действовать более эффективно и гибко в реальных условиях.
Ключевым способом реализации агентов разработчики видят схему «когнитивных архитектур». Её ключевые моменты:
1. Агенты расширяют возможности языковых моделей, используя инструменты для доступа к актуальной информации и выполнения сложных задач автономно. В своей работе они могут использовать одну или несколько LLM для принятия решений о том, как перейти через состояния и использовать внешние инструменты для решения различных задач, которые было бы сложно или невозможно решить с помощью одной модели.
2. Основой работы агента является слой оркестрации — когнитивная архитектура, которая структурирует процессы рассуждения, планирования, принятия решений и направляет действия агента. Различные методы рассуждений, такие как ReAct, Chain-of-Thought и Tree-of-Thoughts, предоставляют структуру для слоя оркестрации, который собирает информацию, обрабатывает ее, генерирует ответы или стимулирует действия.
3. Инструменты — расширения, функции и хранилища данных — служат «ключами» к внешнему миру для агентов, позволяя им взаимодействовать с внешними системами и получать доступ к знаниям за пределами обучающих данных. Расширения соединяют агентов с внешними API для получения актуальной информации. Функции дают разработчикам более детальный контроль над потоком данных и выполнением операций. Хранилища данных открывают доступ к структурированным или неструктурированным данным, поддерживая приложения, основанные на извлечении знаний.
Ожидается, что в будущем агенты покажут значительные достижения благодаря усовершенствованию инструментов и возможностей вести рассуждения. Это позволит им решать все более сложные задачи.
Кроме того, стратегический подход «цепочки агентов», объединяющий специализированных агентов для конкретных задач, будет способствовать созданию комплексных систем, работающих наподобие конвейера, каждое звено которого выполняет свою функцию.
#news #AI #бигтехи #политика
https://www.kaggle.com/whitepaper-agents
Kaggle
Agents
Authors: Julia Wiesinger, Patrick Marlow and Vladimir Vuskovic