
Эшу быдлокодит
Ссылка в репосте оказалась битой, вот рабочая ссылка на то же самое исследование. Прочту статью, выскажусь по теме в Футуризм или сюда.
Вообще, лидар - это дальномер. До чего же дошла техника, что по показаниям дальномера из робота-пылесоса можно считать звук! Ведь физический принцип регистрации звука в описанном эксперименте таков: фиксируется, насколько вы своими голосами деформируете стены и другие твердые приборы у вас дома.
Для оптики это более-менее фиксируемые величины: порядка сотен нанометров, но звук забивается шумами и вибрациями большого города: то же метро чувствительно (для оптики) сотрясает землю в радиусе около километра, если не больше.
Следующей проблемой стало то, что лидар в роботе-пылесосе хреновенький, при этом, если правильно его хакнуть, частота регистрируемых им данных составит 1.8 кГц, минимальная необходимая для нормальной записи голоса частота - 5 кГц.
В итоге ученые, используя всю мощь современной цифровой обработки сигналов, сумели подавить шумы окружающей среды, но проблема низкого качества звука никуда не делась. Для её решения использовались нейросети: их обучили восстанавливать звук, фиксированный на микрофон с недостаточной частотой измерения. В итоге результатом всех этих манипуляций стало достижение 90%й точности фиксации голоса человека, что очень даже неплохо.
Смогут ли злоумышленники пройти этот путь, чтобы шпионить за вами - думайте сами.
Для оптики это более-менее фиксируемые величины: порядка сотен нанометров, но звук забивается шумами и вибрациями большого города: то же метро чувствительно (для оптики) сотрясает землю в радиусе около километра, если не больше.
Следующей проблемой стало то, что лидар в роботе-пылесосе хреновенький, при этом, если правильно его хакнуть, частота регистрируемых им данных составит 1.8 кГц, минимальная необходимая для нормальной записи голоса частота - 5 кГц.
В итоге ученые, используя всю мощь современной цифровой обработки сигналов, сумели подавить шумы окружающей среды, но проблема низкого качества звука никуда не делась. Для её решения использовались нейросети: их обучили восстанавливать звук, фиксированный на микрофон с недостаточной частотой измерения. В итоге результатом всех этих манипуляций стало достижение 90%й точности фиксации голоса человека, что очень даже неплохо.
Смогут ли злоумышленники пройти этот путь, чтобы шпионить за вами - думайте сами.
В общем-то у меня дипломная работа была как раз про запись звука с помощью лазерного излучения, правда у нас был чуть другой сетап установки: вместо лазера, направленного на твердую поверхность, был лазерный свет идущий по оптическому волокну.
Суть эксперимента такая: лазерный свет разделяется между двумя волокнами: опорным, где он не петерпевает никаких воздействий и измерительным, воздействие на которое мы пытаемся фиксировать. Воздействие - звуковые колебания - немного растягивают и сжимают волокно, потому свет в нем обретает небольшую дополнительную задержку.
После этого с помощью небольшой магии (волоконно-оптический разветвитель 3х3, суть магии описывается 10 страницами решения системы дифференциальных уравнений) и коротенького скрипта в SciLab можно фиксировать звук. В общем получается классический интерферометр, очень похожий по сути и математическому аппарату на тот, что у меня в диссертации используется, только вместо здоровенного микроскопа в 50 кг на столе валяются мотки желтенького оптического волокна.
Мы пытались регистрировать воздействия, передающиеся через воздух, но потерпели фиаско, видимо для нормального результата надо было использовать концертные колонки. Потом попробовали подать звук по модели твердой среды (пьезокерамический элемент), и даже получилось. Без всяких математических шаманств качество звука получилось вполне достойное, аудиофайл записи, пропущенной через пьезокерамику, волокно и записанной прикладываю ниже.
Суть эксперимента такая: лазерный свет разделяется между двумя волокнами: опорным, где он не петерпевает никаких воздействий и измерительным, воздействие на которое мы пытаемся фиксировать. Воздействие - звуковые колебания - немного растягивают и сжимают волокно, потому свет в нем обретает небольшую дополнительную задержку.
После этого с помощью небольшой магии (волоконно-оптический разветвитель 3х3, суть магии описывается 10 страницами решения системы дифференциальных уравнений) и коротенького скрипта в SciLab можно фиксировать звук. В общем получается классический интерферометр, очень похожий по сути и математическому аппарату на тот, что у меня в диссертации используется, только вместо здоровенного микроскопа в 50 кг на столе валяются мотки желтенького оптического волокна.
Мы пытались регистрировать воздействия, передающиеся через воздух, но потерпели фиаско, видимо для нормального результата надо было использовать концертные колонки. Потом попробовали подать звук по модели твердой среды (пьезокерамический элемент), и даже получилось. Без всяких математических шаманств качество звука получилось вполне достойное, аудиофайл записи, пропущенной через пьезокерамику, волокно и записанной прикладываю ниже.
Forwarded from Архив КС/РФ(Сиона-Футуриста) (Красный)
Написание ботов для телеграма — одно из самых распространённых развлечений программистов, обычно начинающих.
В принципе, бот достаточно удачный выбор личного проекта для саморазвития. Более-менее качественная документация, большое число коллег имевших дело с ботами.
Начать писать бота очень легко: запрос гуглу вида "язык такой-то телеграм бот" как правило сразу вываливает статью на хабре с рабочими кусками кода. 5 минут и первый бот, не умеющий еще ничего, но уже рабочий, у тебя готов.
При этом, написание сколько-нибудь удобного и функционального бота потребует существенно больше усилий: придется работать с базами данных, ставить ограничения на частоту запросов, продумывать и реализовывать логику.
Собственно, некоторые наши боты — Футуристъ и один из ботов для обратной связи были тем самым проектом для самообразования, которым я занимался в конце лета-начале осени, о чем периодически отписывался в свой дневничек.
Телеграм предоставляет возможность взаимодействовать всем желающим со своей экосистемой. Любой разработчик может начать писать ботов на любом языке (но на некоторых есть готовые решения для ботов, что сильно упрощает жизнь).
Наткнулся на интересный проект: один итальянец написал телеграм бота на ассемблере под Intel Core i5 6600. Ассемблер - язык позволяющий работать напрямую с процессором — это буквально хтоническое чудовище из прошлого. Один из наиболее оторванных от обыденности языков программирования, занимающий узкую нишу взаимодействия непосредственно с железом, но и оттуда вытесняемый С.
Проект ассемблерного бота — чисто образовательный, не имеющий никакой ценности кроме углубления знаний и радости для программиста, который смог сделать ЭТО. Неслучайно проект называется: Just 4fun Telegram Bot. то бишь "бот чисто для лулзов".
Eshu Marabo
В принципе, бот достаточно удачный выбор личного проекта для саморазвития. Более-менее качественная документация, большое число коллег имевших дело с ботами.
Начать писать бота очень легко: запрос гуглу вида "язык такой-то телеграм бот" как правило сразу вываливает статью на хабре с рабочими кусками кода. 5 минут и первый бот, не умеющий еще ничего, но уже рабочий, у тебя готов.
При этом, написание сколько-нибудь удобного и функционального бота потребует существенно больше усилий: придется работать с базами данных, ставить ограничения на частоту запросов, продумывать и реализовывать логику.
Собственно, некоторые наши боты — Футуристъ и один из ботов для обратной связи были тем самым проектом для самообразования, которым я занимался в конце лета-начале осени, о чем периодически отписывался в свой дневничек.
Телеграм предоставляет возможность взаимодействовать всем желающим со своей экосистемой. Любой разработчик может начать писать ботов на любом языке (но на некоторых есть готовые решения для ботов, что сильно упрощает жизнь).
Наткнулся на интересный проект: один итальянец написал телеграм бота на ассемблере под Intel Core i5 6600. Ассемблер - язык позволяющий работать напрямую с процессором — это буквально хтоническое чудовище из прошлого. Один из наиболее оторванных от обыденности языков программирования, занимающий узкую нишу взаимодействия непосредственно с железом, но и оттуда вытесняемый С.
Проект ассемблерного бота — чисто образовательный, не имеющий никакой ценности кроме углубления знаний и радости для программиста, который смог сделать ЭТО. Неслучайно проект называется: Just 4fun Telegram Bot. то бишь "бот чисто для лулзов".
Eshu Marabo
Forwarded from Архив КС/РФ(Сиона-Футуриста) (Красный)
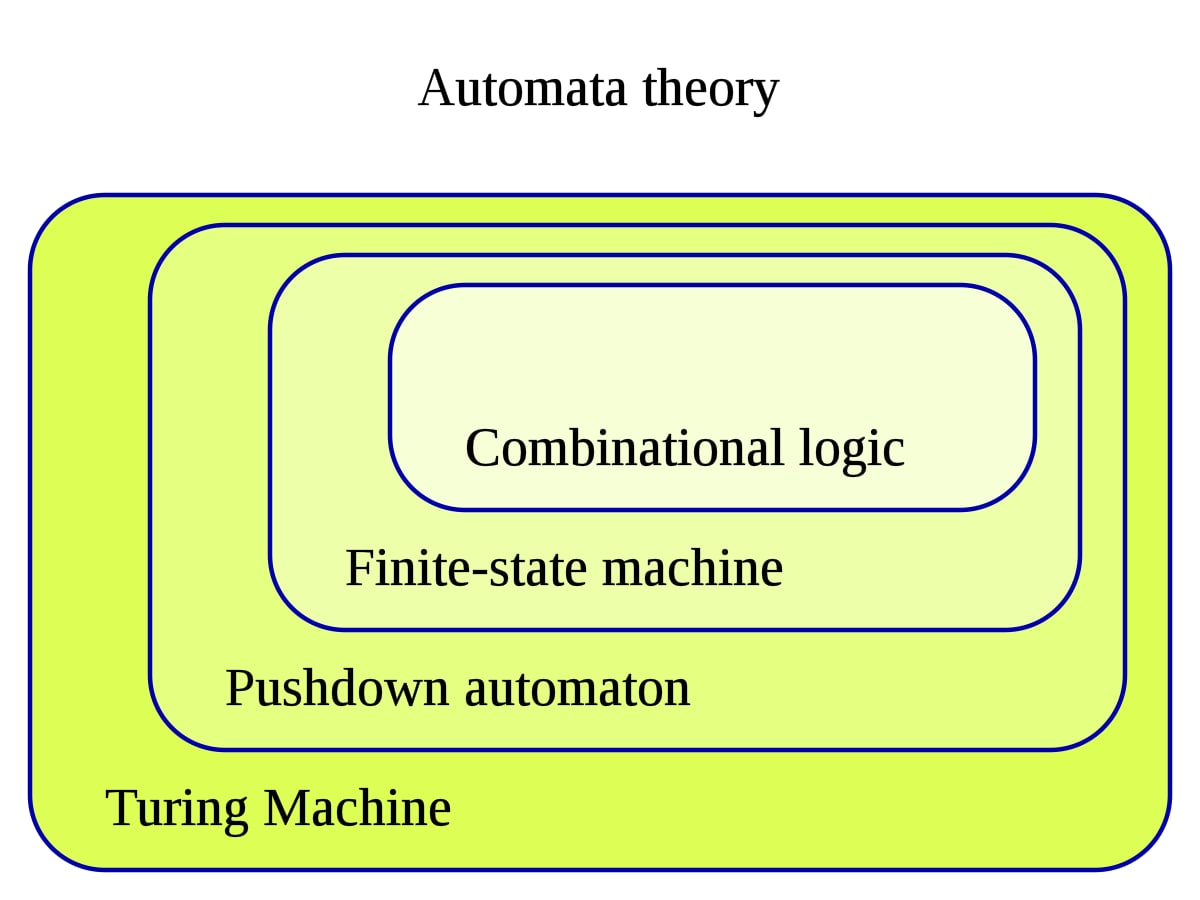
Занятно читать про истоки возникновения современного IT. В середине ХХ века были разработаны все основные концепции, которые сейчас используются программистами по всему миру каждый день. Одной из таких концепций стала теория автоматов.
В ее рамках, рассматриваются абстрактные сущности, "автоматы", которые могут выполнять определенный набор действий в зависимости от определенного набора команд, подаваемых из внешнего мира.
В те благословенные дремучие времена такими автоматами вполне можно было адекватно описать ЭВМ: есть набор инструкций (передаваемых, например, с помощью перфокарт), на каждую из них есть строго определенная реакция.
Современный ПК так описать можно, но проще в восприятии от этого он не станет, даже несмотря на то, что набор инструкций процессора по-прежнему конечен. Пусть данные, в предельном упрощении, это набор ноликов и единичек, но концепция автоматов на практике нужна мало: современные языки программирования и парадигмы и так полны абстракций для описания всего на свете.
Зато в качестве элемента (само)образования теория автоматов вполне полезная в подготовке программиста: эта модель описания реальности позволяет посмотреть на модули программного обеспечения с другого ракурса, сосредоточившись на их функциональности, абстрагируясь от нюансов реализации.
Этот подход особенно полезен при тестировании и в геймдеве: состояния юнитов, игровые события, действия игрока, действия ИИ. Всё это должно увязываться в единую схему, понятную не только программистам. Перегружать ее особенностями реализации компонентов совершенно излишне.
Eshu Marabo
В ее рамках, рассматриваются абстрактные сущности, "автоматы", которые могут выполнять определенный набор действий в зависимости от определенного набора команд, подаваемых из внешнего мира.
В те благословенные дремучие времена такими автоматами вполне можно было адекватно описать ЭВМ: есть набор инструкций (передаваемых, например, с помощью перфокарт), на каждую из них есть строго определенная реакция.
Современный ПК так описать можно, но проще в восприятии от этого он не станет, даже несмотря на то, что набор инструкций процессора по-прежнему конечен. Пусть данные, в предельном упрощении, это набор ноликов и единичек, но концепция автоматов на практике нужна мало: современные языки программирования и парадигмы и так полны абстракций для описания всего на свете.
Зато в качестве элемента (само)образования теория автоматов вполне полезная в подготовке программиста: эта модель описания реальности позволяет посмотреть на модули программного обеспечения с другого ракурса, сосредоточившись на их функциональности, абстрагируясь от нюансов реализации.
Этот подход особенно полезен при тестировании и в геймдеве: состояния юнитов, игровые события, действия игрока, действия ИИ. Всё это должно увязываться в единую схему, понятную не только программистам. Перегружать ее особенностями реализации компонентов совершенно излишне.
Eshu Marabo
{kind=link}
На 5 курсе я, с подачи заведующего кафедрой, учился не в нашем вузе, а на экспериментальной образовательной программе от корпорации. В комплекте с образованием шло трудоустройство. Всё было прекрасно, но за весь год я был только на одной паре и то по ошибке.
Не все преподаватели отнеслись с восторгам к экспериментам заведующего, потому обе сессии были весёлыми.
С тех пор (прошло уже почти 10 лет) мне периодически снится, что грядет сессия, я пропустил весь семестр, и вот буквально через несколько дней мне надо сдавать нечто ядрёное, замешанное на матане.
Кстати, маму такие сны преследуют и через 30 лет после окончания вуза.
Не все преподаватели отнеслись с восторгам к экспериментам заведующего, потому обе сессии были весёлыми.
С тех пор (прошло уже почти 10 лет) мне периодически снится, что грядет сессия, я пропустил весь семестр, и вот буквально через несколько дней мне надо сдавать нечто ядрёное, замешанное на матане.
Кстати, маму такие сны преследуют и через 30 лет после окончания вуза.
А вам снятся сессии или другие моменты из вуза, связанные с учёбой?
Final Results
48%
Да, было (или есть) весело и страшно.
34%
Нет, всё сдано без проблем
3%
Я не учился в вузе
15%
Посмотреть результаты
Эшу быдлокодит
А вам снятся сессии или другие моменты из вуза, связанные с учёбой?
От подписчика: Мне снится, что я какого-то хрена попал в армию, хотя там уже был
Знакомый учится в Оксфорде, гуманитарная специальность. В качестве вспомогательного языка программирования им будут давать R.
Далее цитата, очищенная от мата, оставлю без дополнительных комментариев:
"У нас в Оксфорде будет целый семестр R
При чем все исследователи прямо говорят что питон раз в сто лучше
Но ему не учат
Так как не могут
Чертовы гуманитарии
Лучший университет мира
Центр знаний с начала тысячелетия
Вот на кой хрен мне ваш R, если питон лучше
Просто социологи обожают R
Ибо питон считается сложным"
Далее цитата, очищенная от мата, оставлю без дополнительных комментариев:
"У нас в Оксфорде будет целый семестр R
При чем все исследователи прямо говорят что питон раз в сто лучше
Но ему не учат
Так как не могут
Чертовы гуманитарии
Лучший университет мира
Центр знаний с начала тысячелетия
Вот на кой хрен мне ваш R, если питон лучше
Просто социологи обожают R
Ибо питон считается сложным"
Forwarded from Архив КС/РФ(Сиона-Футуриста) (Красный)
Все слышали понятие "база данных" - некоторая совокупность структурированных данных о каком-либо предмете. Кроме него есть другое понятие - "база знаний". В современной it терминологии есть двойственность: базами знаний называют как wiki - подобные справочные системы, так и то, чем они являлись изначально: хранилищами правил обработки информации. Предельное развитие таких баз знаний - экспертные системы.
Экспертные системы позволяли творить магию искусственного интеллекта довольно давно, и, что характерно, без хипстеров-датасатанистов, нейросетей, сопутствующего матана и видеокарт, на которых можно пожарить яичницу.
Разработать экспертную систему относительно несложно, но очень трудозатратно.
Первая задача - разработать формальную модель знаний. Как вариант, это может быть графовая структура, описывающая взаимосвязи между различными фактами.
Приведу простой пример формализованного знания. При машинном анализе русскоязычных предложений нужно найти прилагательные, относящиеся к существительному-подлежащему. Логика подсказывает, что все прилагательные в этом предложении, имеющие тот же род и падеж, что и подлежащее, будут относиться к нему. Совокупность таких правил и исключений к ним позволяет составить базу знаний русского языка.
Модель знаний нужно снабдить удобным интерфейсом для ввода новых и редактивания старых знаний. После этого нужно нанять экспертов, которые сядут и десятки, а то и сотни человеко-лет будут вбивать в систему свои знания и опыт.
Подобные системы позволяют делать многое, например работать ассистентом врача. Недобросовестное отношение при разработке может приводить к катастрофическим последствиям: достаточно вспомнить эпидемию опиатных смертей в США, которая произошла по причине сговора создателя экспертной системы и фарм-компании.
Eshu Marabo
Экспертные системы позволяли творить магию искусственного интеллекта довольно давно, и, что характерно, без хипстеров-датасатанистов, нейросетей, сопутствующего матана и видеокарт, на которых можно пожарить яичницу.
Разработать экспертную систему относительно несложно, но очень трудозатратно.
Первая задача - разработать формальную модель знаний. Как вариант, это может быть графовая структура, описывающая взаимосвязи между различными фактами.
Приведу простой пример формализованного знания. При машинном анализе русскоязычных предложений нужно найти прилагательные, относящиеся к существительному-подлежащему. Логика подсказывает, что все прилагательные в этом предложении, имеющие тот же род и падеж, что и подлежащее, будут относиться к нему. Совокупность таких правил и исключений к ним позволяет составить базу знаний русского языка.
Модель знаний нужно снабдить удобным интерфейсом для ввода новых и редактивания старых знаний. После этого нужно нанять экспертов, которые сядут и десятки, а то и сотни человеко-лет будут вбивать в систему свои знания и опыт.
Подобные системы позволяют делать многое, например работать ассистентом врача. Недобросовестное отношение при разработке может приводить к катастрофическим последствиям: достаточно вспомнить эпидемию опиатных смертей в США, которая произошла по причине сговора создателя экспертной системы и фарм-компании.
Eshu Marabo
Диссертационный проект - это ПО для микроскопа. Нужно на лету обрабатывать поток изображений, представленных в виде массивов чисел (double). Одно из потенциальных узких по производительности мест - скорость копирования данных из массива в массив.
Для того, чтобы определить оптимальный способ копирования, плюс померять некоторые другие параметры я использовал инструмент BenchmarkDotNet 0.12.1. На картинках представлены результаты замеров для массива размером 1000х2000.
По таблицам в иллюстрациях:
CreateNew - замер скорости создания массива
AllItemIter - замер скорости обхода всего массива с присвоением значений.
Clone - замер скорости копирования всего массива с сипользованием стандартного метода Clone()
CopyByItem - замер скорости копирования всех элементов в созданный пустой массив с автоопределением размеров массива
CopyByItemExistSizes -замер скорости копирования всех элементов в созданный пустой массив без автоопределения размеров массива
Недавно вышел релиз платформы .Net 5.0, проводил замеры для нее и прошлой версии - .Net Core 3.1.
Итого, результаты теста:
1. Клонирование массива - самый быстрый вариант. При переходе с .Net Core 3.1 на 5 версию его ускорили в 3(!) раза!
2. Автоопределение размеров массива с помощью метода GetUpperBound() - плохая идея, пустая трата вычислительных ресурсов.
3. При переходе на новую версию в принципе все действия над массивами были чуть ускорены.
Код бенчмарка прикладываю в файле ниже.
#csharp #диссер
Для того, чтобы определить оптимальный способ копирования, плюс померять некоторые другие параметры я использовал инструмент BenchmarkDotNet 0.12.1. На картинках представлены результаты замеров для массива размером 1000х2000.
По таблицам в иллюстрациях:
CreateNew - замер скорости создания массива
AllItemIter - замер скорости обхода всего массива с присвоением значений.
Clone - замер скорости копирования всего массива с сипользованием стандартного метода Clone()
CopyByItem - замер скорости копирования всех элементов в созданный пустой массив с автоопределением размеров массива
CopyByItemExistSizes -замер скорости копирования всех элементов в созданный пустой массив без автоопределения размеров массива
Недавно вышел релиз платформы .Net 5.0, проводил замеры для нее и прошлой версии - .Net Core 3.1.
Итого, результаты теста:
1. Клонирование массива - самый быстрый вариант. При переходе с .Net Core 3.1 на 5 версию его ускорили в 3(!) раза!
2. Автоопределение размеров массива с помощью метода GetUpperBound() - плохая идея, пустая трата вычислительных ресурсов.
3. При переходе на новую версию в принципе все действия над массивами были чуть ускорены.
Код бенчмарка прикладываю в файле ниже.
#csharp #диссер
Telegram
Эшу быдлокодит
Forwarded from Архив КС/РФ(Сиона-Футуриста) (Красный)
Последние годы интеллектуальные системы, основанные на машинном обучении были на пике хайпа. Как правило, именно их имеют ввиду, когда говорят об ИИ. Для пользователя, пользующегося умным программным продуктом, разницы между экспертными системами, построенными на основе базы знаний или же обработки бигдаты нет никакой. При этом, "под капотом" она принципиальна.
Классические экспертные системы выступают как хранилище знаний, созданных человеком. Системы на базе машинного обучения же, на основе некоторых математических манипуляций, извлекают новые, "нелюдские" правила обработки данных.
Системы на базе машинного обучения ощутимо быстрее в разработке: тут работает закон перехода количества в качество: рост объемов исходных данных и вычислительных мощностей дают возможность творить магию, затрачивая сравнительно меньше человеко-часов.
Специалисты по анализу данных универсальны: математическая подготовка и используемые инструменты более-менее универсальны во всех областях. Сегодня дата-саентист работает с рентгеновскими снимками, завтра делает систему ориентирования робота в пространстве. А суперкомпьютеру, на котором он экспериментирует вообще все равно что считать.
При разработке экспертной системе же требуется постоянный поиск высокооплачиваемых специалистов. После открытия нового направления экспертную группу можно менять в полном составе или удваивать личный состав.
Нейросеть, или другую модель, полученную при обучении отчасти можно назвать базой знаний, но логика ее работы совершенно непрозрачна — в отличии от экспертных систем, играющих по заданным правилам.
Системы на базе машинного обучения имеют неприятную особенность: они могут сходить с ума, как в результате стечения обстоятельств, так и по человеческому умыслу.
Потому в сердце систем, на которые завязаны жизнь и смерть человека, таких, как автопилот в автомобиле или ассистент врача, в обозримой перспективе будут классические экспертные системы. При этом "на периферии", в части взаимодействия с внешним миром, уже сейчас царство нейросетей, которые так и не превзошли в задачах класса "распознать силуэт человека во мраке".
Так что будущее мне видится в слиянии двух подходов — человеческого и машинного.
Eshu Marabo
Классические экспертные системы выступают как хранилище знаний, созданных человеком. Системы на базе машинного обучения же, на основе некоторых математических манипуляций, извлекают новые, "нелюдские" правила обработки данных.
Системы на базе машинного обучения ощутимо быстрее в разработке: тут работает закон перехода количества в качество: рост объемов исходных данных и вычислительных мощностей дают возможность творить магию, затрачивая сравнительно меньше человеко-часов.
Специалисты по анализу данных универсальны: математическая подготовка и используемые инструменты более-менее универсальны во всех областях. Сегодня дата-саентист работает с рентгеновскими снимками, завтра делает систему ориентирования робота в пространстве. А суперкомпьютеру, на котором он экспериментирует вообще все равно что считать.
При разработке экспертной системе же требуется постоянный поиск высокооплачиваемых специалистов. После открытия нового направления экспертную группу можно менять в полном составе или удваивать личный состав.
Нейросеть, или другую модель, полученную при обучении отчасти можно назвать базой знаний, но логика ее работы совершенно непрозрачна — в отличии от экспертных систем, играющих по заданным правилам.
Системы на базе машинного обучения имеют неприятную особенность: они могут сходить с ума, как в результате стечения обстоятельств, так и по человеческому умыслу.
Потому в сердце систем, на которые завязаны жизнь и смерть человека, таких, как автопилот в автомобиле или ассистент врача, в обозримой перспективе будут классические экспертные системы. При этом "на периферии", в части взаимодействия с внешним миром, уже сейчас царство нейросетей, которые так и не превзошли в задачах класса "распознать силуэт человека во мраке".
Так что будущее мне видится в слиянии двух подходов — человеческого и машинного.
Eshu Marabo
Весь вечер гоняю замеры скорости для диссертационного проекта. Пока складывается ощущение, что я попросту ошибся с языком: самая вычислительно сложная часть, сделанная в виде копипасты куска кода на С, работает быстрее примитивнейших операций, написанных на С#.
Постараюсь выжать из шарпа по-максимуму, но пока вдалеке мне видится кошмарная глыба С++ надвигающаяся на меня.
Постараюсь выжать из шарпа по-максимуму, но пока вдалеке мне видится кошмарная глыба С++ надвигающаяся на меня.
Эшу быдлокодит pinned «Создал небольшой дневничок. Тут будет IT, немного науки и что-то из жизни препода. А также репосты понравившихся новостей. Политоты не будет. Кратко обо мне. Один из авторов канала @rufuturism, программист, препод в одном из средних московских ВУЗов на 0.1…»
О пользе нормального DevOps, точнее о вреде его отсутствия.
Мне нужно было внести мизерную правку в моих ботов: добавить логику обработки пересланных в бота для обратной связи сообщений.
Если сообщение - пересланное (т.е. свойство ForwardFrom у него не пустое), вызываем функцию пересылки и пересылаем его. Добавил минуты за полторы. А потом началось веселье. Мои боты стоят на линукс сервере, там же PostgreSQL, к которой они цепляются. Ботов, которыми пользуются люди, как бы "прод", я обновляю простеньким скриптом для командной строки на 20 строчек.
В какой-то момент я утратил последнюю версию скрипта и откладывал это обновление три (!) недели, т.к. писать скрипт с нуля - часов 5 рабочего времени, накатывать обновление руками - вообще непонятно сколько, т.к. что-то обязательно забудешь, после чего последует долгое восстановление.
И вот нашелся скрипт и обновления и фиксы стали накатываться сразу после проверки локально. А не поленился бы я научиться настраивать CD/CI - например Github Actions - проблем бы не было вообще: все проверки и автодеплой запускались бы из моего аккаунта на Github.
Мне нужно было внести мизерную правку в моих ботов: добавить логику обработки пересланных в бота для обратной связи сообщений.
Если сообщение - пересланное (т.е. свойство ForwardFrom у него не пустое), вызываем функцию пересылки и пересылаем его. Добавил минуты за полторы. А потом началось веселье. Мои боты стоят на линукс сервере, там же PostgreSQL, к которой они цепляются. Ботов, которыми пользуются люди, как бы "прод", я обновляю простеньким скриптом для командной строки на 20 строчек.
В какой-то момент я утратил последнюю версию скрипта и откладывал это обновление три (!) недели, т.к. писать скрипт с нуля - часов 5 рабочего времени, накатывать обновление руками - вообще непонятно сколько, т.к. что-то обязательно забудешь, после чего последует долгое восстановление.
И вот нашелся скрипт и обновления и фиксы стали накатываться сразу после проверки локально. А не поленился бы я научиться настраивать CD/CI - например Github Actions - проблем бы не было вообще: все проверки и автодеплой запускались бы из моего аккаунта на Github.
Немного погрузился по работе в малость подзабытые нейросети. Оказалось, что за два года, которые прошли с момента, когда я изучал их, мои знания малость протухли.
Появилась новаях архитектура сетей - transformer. Буду разбираться.
Я конечно знаю, что IT развивается стремительно, но не настолько же. Как калейдоскоп фреймворков на js для фронтэнда блин.
Появилась новаях архитектура сетей - transformer. Буду разбираться.
Я конечно знаю, что IT развивается стремительно, но не настолько же. Как калейдоскоп фреймворков на js для фронтэнда блин.
Forwarded from Архив КС/РФ(Сиона-Футуриста) (Красный)
Язык машины
Мы продолжаем писать о практических применениях машинного обучения и том, что скрыто под его "капотом".
Одно из самых волшебных проявлений современного машинного обучения — работа с естественным языком. Алиса, болтающая без умолку, Порфирьевич, сочиняющий стихи, и множество более утилитарных достижений.
Всё это относится к огромной дисциплине NLP Это natural language processing, то есть "обработка естественного языка", а вовсе не псевдонаучное "нейролингвистическое программирование".
NLP появилось примерно тогда же, когда первые ЭВМ: очень заманчиво отдавать команды компьютеру на родном языке. Даже в те лохматые времена уже были первые "алисы", способные корректно обработать абстракции и нелогичности в нашей речи. Однако, катастрофически не хватало вычислительных мощностей и математического аппарата, равно как его общедоступных реализаций.
Примерный путь был понятен чуть ли не с XIX века: словам с близкими значениями присваивать близкие численные аналоги, после чего естественный язык становится более-менее доступным для формального анализа.
Значения цифрового отображения слов "собака", "собачка", "пёс", "псина" будут близкими, но в то же время будут достаточно сильно отличаться от "кошки", и совсем отличаться от "планеты". При этом, стандартный для статистических методов подход "больше данных -> больше профита" нивелировался стандартной же проблемой "больше данных -> больше мусора в них".
Большой прорыв случился в 2013 году, когда никому неизвестный на тот момент чешский аспирант Томаш Миколов предложил новый подход к представлению слов в численном виде: учитывать не только значение самого слова, но и набор ближайших к нему слов. Мы видим к чему это привело через семь лет.
Приведенные к численным значениям слова уже доступны для обработки нейросетями. Кроме того, доступны большие наборы данных как текстов, так и "оцифрованных" словарей. Так, по ссылке доступно для свободного скачивания 150 Гб русскоязычных текстов и 14 Гб уже готовой к использованию "оцифровки".
Для применения в каких-либо "общеязыковых" задачах и анализу текста на русском литературном языке всё готово. Открываем Google Colaboratory, скачиваем датасеты, открываем хабр и чувствуем себя настоящим специалистом по данным. А вот небольшой шажок в сторону — например анализ специфического сленга или терминов потребует существенно больше усилий.
Eshu Marabo
Мы продолжаем писать о практических применениях машинного обучения и том, что скрыто под его "капотом".
Одно из самых волшебных проявлений современного машинного обучения — работа с естественным языком. Алиса, болтающая без умолку, Порфирьевич, сочиняющий стихи, и множество более утилитарных достижений.
Всё это относится к огромной дисциплине NLP Это natural language processing, то есть "обработка естественного языка", а вовсе не псевдонаучное "нейролингвистическое программирование".
NLP появилось примерно тогда же, когда первые ЭВМ: очень заманчиво отдавать команды компьютеру на родном языке. Даже в те лохматые времена уже были первые "алисы", способные корректно обработать абстракции и нелогичности в нашей речи. Однако, катастрофически не хватало вычислительных мощностей и математического аппарата, равно как его общедоступных реализаций.
Примерный путь был понятен чуть ли не с XIX века: словам с близкими значениями присваивать близкие численные аналоги, после чего естественный язык становится более-менее доступным для формального анализа.
Значения цифрового отображения слов "собака", "собачка", "пёс", "псина" будут близкими, но в то же время будут достаточно сильно отличаться от "кошки", и совсем отличаться от "планеты". При этом, стандартный для статистических методов подход "больше данных -> больше профита" нивелировался стандартной же проблемой "больше данных -> больше мусора в них".
Большой прорыв случился в 2013 году, когда никому неизвестный на тот момент чешский аспирант Томаш Миколов предложил новый подход к представлению слов в численном виде: учитывать не только значение самого слова, но и набор ближайших к нему слов. Мы видим к чему это привело через семь лет.
Приведенные к численным значениям слова уже доступны для обработки нейросетями. Кроме того, доступны большие наборы данных как текстов, так и "оцифрованных" словарей. Так, по ссылке доступно для свободного скачивания 150 Гб русскоязычных текстов и 14 Гб уже готовой к использованию "оцифровки".
Для применения в каких-либо "общеязыковых" задачах и анализу текста на русском литературном языке всё готово. Открываем Google Colaboratory, скачиваем датасеты, открываем хабр и чувствуем себя настоящим специалистом по данным. А вот небольшой шажок в сторону — например анализ специфического сленга или терминов потребует существенно больше усилий.
Eshu Marabo
{kind=link}