
tgoop.com/BDataScienceM/2541
Last Update:
Тотальное Уничтожение Multihead-Attention
Для начала вам стоит прочитать пост про Self-Attention для более лучшего понимания данного поста. Если ты действительно хочешь понять MHA, то к данному посту нужно подходить ни один раз, спрашивая в комментах или у GPT.
Главная суть MHA - Multihead Attention
- Распараллеливание: Каждая голова в MHA обрабатывается независимо, что позволяет эффективно использовать вычислительные ресурсы (например, GPU).
- Интерпретация разных смыслов: Разные головы фокусируются на различных аспектах текста, что помогает модели "замечать" важные связи между словами с разных точек зрения.
Детальный разбор
Представим, что batch_size=1, seq_len=4, embedding_dim=6, heads=3 (количество голов).
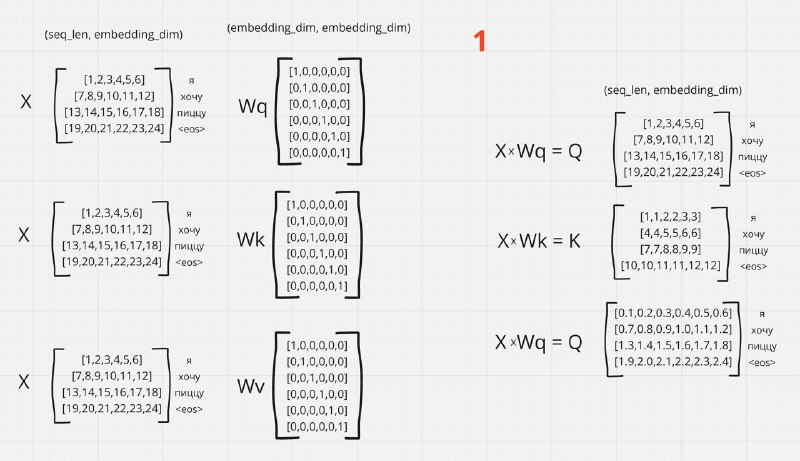
На вход поступает последовательность ["Я", "Хочу", "Пиццу", "<eos>"]. Каждый токен - это слово, которое преобразуется в эмбеддинг (вектор). На выходе имеем матрицу эмбеддингов X, смотрите на картинку 1
Картинка 1:
- На вход в MHA поступает матрица эмбеддингов X.
- Имеем веса Wq, Wk, Wv, которые обучаются.
- Путём матричного умножения X на Wq, Wk, Wv получаем три матрицы: Q, K, V.
Размерности:
- X → (batch_size, seq_len, embedding_dim)
- Wq, Wk, Wv → (embedding_dim, embedding_dim)
- Q, K, V → (batch_size, seq_len, embedding_dim)
Картинка 2:
Вот у нас получились матрицы Q, K, V. Важно понимать, что MHA — это не создание новых отдельных матриц Q, K, V, а деление каждой из них на головы.
Условно, для каждого токена мы уменьшаем длину его вектора, разделяя его между головами. Например, на картинке 2 токен "пиццу" изначально представлен эмбеддингом длиной 6 → [13,14,15,16,17,18]. Если количество голов равно 3, то теперь этот токен преобразуется в 3 вектора по 2 элемента каждый → [[13,14],[15,16],[17,18]], теперь токен "пиццу" представили как три вектора с размером вектора два. Для этого выполняются операции reshape и swap, у нас появляется новая переменная head_dim = embedding_dim/heads
Размерности:
- Q, K, V → (batch_size, seq_len, embedding_dim) = (1, 4, 6)
- Q, K, V после reshape → (batch_size, seq_len, heads, head_dim) = (1, 4, 3, 2)
- Q, K, V после swap → (batch_size, heads, seq_len, head_dim) = (1, 3, 4, 2)
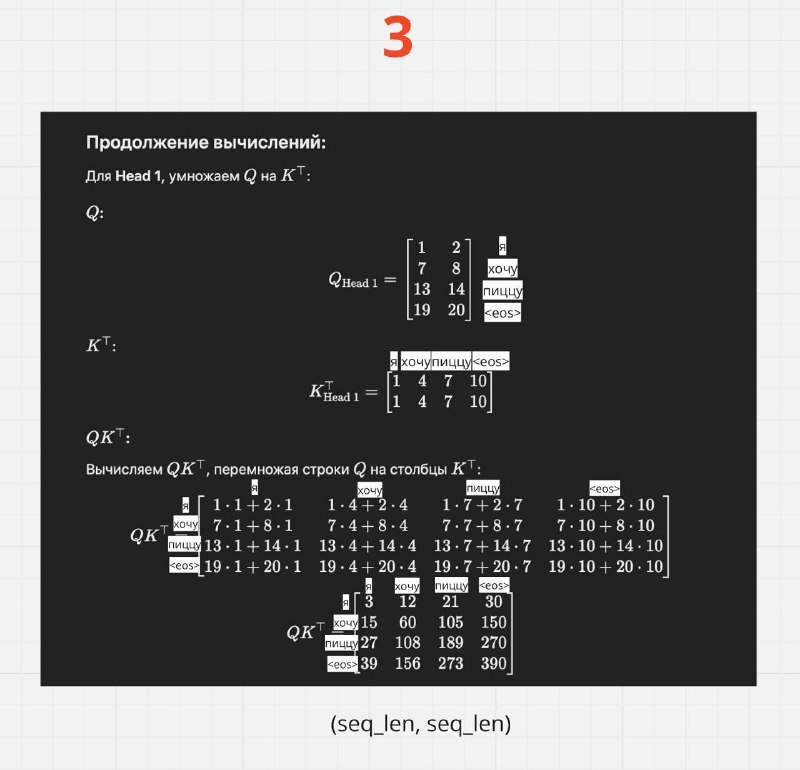
Картинки 3-5:
Теперь происходит обычная формула Self-Attention по каждой голове: softmax((Q x K.T)/sqrt(head_dim)) * V
И основная суть, что каждая голова обрабатывается параллельно на одном устройстве (например, GPU), что обеспечивает эффективное распараллеливание вычислений
Размерности:
Attention Output для каждой головы имеет размерность → (batch_size, seq_len, head_dim) = (1, 4, 2).
Картинки 6-8:
Вот мы посчитали для каждой головы Attention Output, а теперь время всё конкатить, восстанавливая исходную размерность эмбеддингов. Делаем обратные операции что и на втором шаге. Сначала reshape, а потом swap
Размерности:
- Attention Output каждой головы → (batch_size, text, seq_len, head_dim) = (1, 3, 4, 2)
- После swap → (batch_size, seq_len, heads, head_dim)=(1, 4, 3, 2)
- После reshape → (batch_size, seq_len, heads×head_dim)=(1, 4, 6)
Картинка 9:
Ну и наконец-то получаем наш Attention Output, который матрично умножается на матрицу весов Wo: Attention Output x Wo. По итогу получается FinalOutput, которая идёт в следующие слои
Размерности:
- Wo → (embedding_dim, embedding_dim) = (6, 6)
- Attention Output → (batch_size, seq_len, embedding_dim) = (1, 4, 6)
- FinalOutput → (batch_size, seq_len, embedding_dim) = (1, 4, 6)





{kind=link}