
Разговор про выбросы часто выглядит чрезвычайно куцо.
* "Выбросы — это точечки и звездочки на босксплоте."
* "Регрессия / t-тест плохо переваривают выбросы, поэтому их нужно удалять."
* "Если в данных есть выбросы, то нужно использовать непараметрику / ранговые подходы."
И прочее, и прочее.
Редко звучит мысль о том, что не надо просто так удалять выбросы, а стоит задуматься над тем, почему и откуда они взялись в ваших данных, являются ли они органичной частью даты или же это ошибки, хотим ли мы их моделировать, или для нас они экстраординарное явление, которое учитывать в нашей модели мы не хотим. Мысль, что для выбросов стоит предложить вероятностную модель и работать с ними в рамках нее, звучит еще реже.
Теперь слайды.
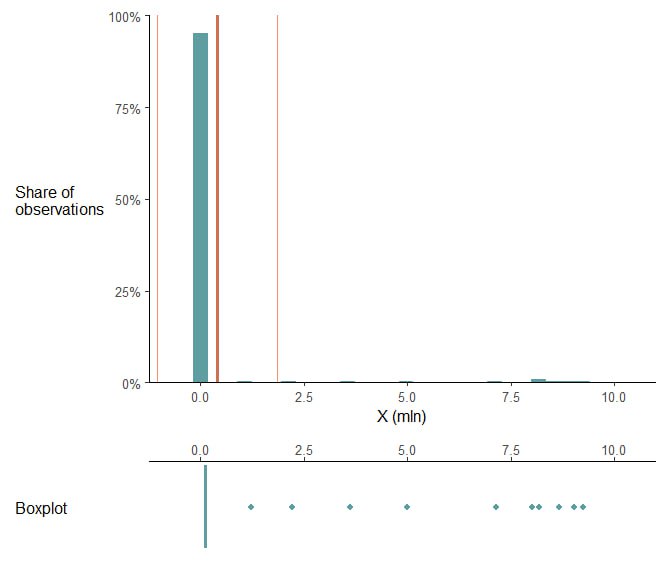
На Рис. 1 сверху представлена гистограмма некоторой величины X, жирной красной линией отмечено среднее, тоненькими +- SD. Снизу пририсован боксплот: он настолько вырожден, что видно только десять выбросов.
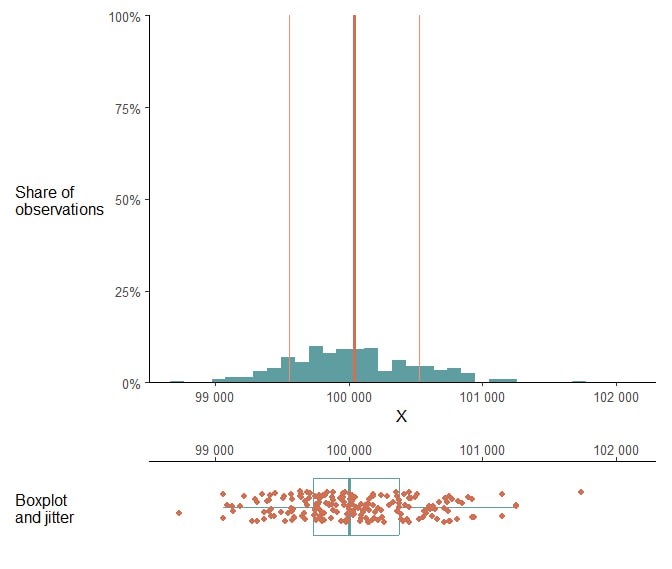
Если мы занимаемся физикой или биомедициной и это наши измерения, то вполне может быть так, что вот эти десять аутлайеров — это какая-то ерунда. Кабель плохо воткнули или при переносе данных кто-то опечатался нулем. В таком случае исключение этих аутлайеров — вполне логичный шаг, который даст нам картинку на Рис. 2.
Посмотрим на это с другой стороны: вы — бузинес, а X — это ваши продажи (отдельные чеки). Действуем так же, как и в прошлый раз, да ведь? Ну хз. На эти ~5% чеков в сумме приходится 60 миллионов выручки, в то время как остальные 200 чеков обеспечивают всего 20 миллионов. Случайность ли это? Или осознанная бизнес-модель, когда реальную выручку вам генерит всего пара крупных контрактов, а все остальное — это скорее маркетинг? Если последнее, то применение ранговых критериев и тем более исключение выбросов сыграет с вами злую шутку.
Наблюдения становятся для нас аутлайерами не потому, что какая-то статистическая процедура пометила их звездочкой. Как мы помним, любой статвывод делается в некоторой вероятностной модели. Поэтому было бы здорово, если бы аналитики явно описывали эту модель, а затем задумывались, подходит ли она под их ситуацию. Выбросами наблюдения становятся только в контексте, и что для одной задачи шум и data contamination, то для другой задачи — норма и совершенно ожидаемое наблюдение.
Больше про работу с выбросами можно узнать вот тут; советую прочитать хотя бы раздел 1.1, он хорошо описывает проблематику.
#statistics
* "Выбросы — это точечки и звездочки на босксплоте."
* "Регрессия / t-тест плохо переваривают выбросы, поэтому их нужно удалять."
* "Если в данных есть выбросы, то нужно использовать непараметрику / ранговые подходы."
И прочее, и прочее.
Редко звучит мысль о том, что не надо просто так удалять выбросы, а стоит задуматься над тем, почему и откуда они взялись в ваших данных, являются ли они органичной частью даты или же это ошибки, хотим ли мы их моделировать, или для нас они экстраординарное явление, которое учитывать в нашей модели мы не хотим. Мысль, что для выбросов стоит предложить вероятностную модель и работать с ними в рамках нее, звучит еще реже.
Теперь слайды.
На Рис. 1 сверху представлена гистограмма некоторой величины X, жирной красной линией отмечено среднее, тоненькими +- SD. Снизу пририсован боксплот: он настолько вырожден, что видно только десять выбросов.
Если мы занимаемся физикой или биомедициной и это наши измерения, то вполне может быть так, что вот эти десять аутлайеров — это какая-то ерунда. Кабель плохо воткнули или при переносе данных кто-то опечатался нулем. В таком случае исключение этих аутлайеров — вполне логичный шаг, который даст нам картинку на Рис. 2.
Посмотрим на это с другой стороны: вы — бузинес, а X — это ваши продажи (отдельные чеки). Действуем так же, как и в прошлый раз, да ведь? Ну хз. На эти ~5% чеков в сумме приходится 60 миллионов выручки, в то время как остальные 200 чеков обеспечивают всего 20 миллионов. Случайность ли это? Или осознанная бизнес-модель, когда реальную выручку вам генерит всего пара крупных контрактов, а все остальное — это скорее маркетинг? Если последнее, то применение ранговых критериев и тем более исключение выбросов сыграет с вами злую шутку.
Наблюдения становятся для нас аутлайерами не потому, что какая-то статистическая процедура пометила их звездочкой. Как мы помним, любой статвывод делается в некоторой вероятностной модели. Поэтому было бы здорово, если бы аналитики явно описывали эту модель, а затем задумывались, подходит ли она под их ситуацию. Выбросами наблюдения становятся только в контексте, и что для одной задачи шум и data contamination, то для другой задачи — норма и совершенно ожидаемое наблюдение.
Больше про работу с выбросами можно узнать вот тут; советую прочитать хотя бы раздел 1.1, он хорошо описывает проблематику.
#statistics
tgoop.com/choking_data/37
Create:
Last Update:
Last Update:
Разговор про выбросы часто выглядит чрезвычайно куцо.
* "Выбросы — это точечки и звездочки на босксплоте."
* "Регрессия / t-тест плохо переваривают выбросы, поэтому их нужно удалять."
* "Если в данных есть выбросы, то нужно использовать непараметрику / ранговые подходы."
И прочее, и прочее.
Редко звучит мысль о том, что не надо просто так удалять выбросы, а стоит задуматься над тем, почему и откуда они взялись в ваших данных, являются ли они органичной частью даты или же это ошибки, хотим ли мы их моделировать, или для нас они экстраординарное явление, которое учитывать в нашей модели мы не хотим. Мысль, что для выбросов стоит предложить вероятностную модель и работать с ними в рамках нее, звучит еще реже.
Теперь слайды.
На Рис. 1 сверху представлена гистограмма некоторой величины X, жирной красной линией отмечено среднее, тоненькими +- SD. Снизу пририсован боксплот: он настолько вырожден, что видно только десять выбросов.
Если мы занимаемся физикой или биомедициной и это наши измерения, то вполне может быть так, что вот эти десять аутлайеров — это какая-то ерунда. Кабель плохо воткнули или при переносе данных кто-то опечатался нулем. В таком случае исключение этих аутлайеров — вполне логичный шаг, который даст нам картинку на Рис. 2.
Посмотрим на это с другой стороны: вы — бузинес, а X — это ваши продажи (отдельные чеки). Действуем так же, как и в прошлый раз, да ведь? Ну хз. На эти ~5% чеков в сумме приходится 60 миллионов выручки, в то время как остальные 200 чеков обеспечивают всего 20 миллионов. Случайность ли это? Или осознанная бизнес-модель, когда реальную выручку вам генерит всего пара крупных контрактов, а все остальное — это скорее маркетинг? Если последнее, то применение ранговых критериев и тем более исключение выбросов сыграет с вами злую шутку.
Наблюдения становятся для нас аутлайерами не потому, что какая-то статистическая процедура пометила их звездочкой. Как мы помним, любой статвывод делается в некоторой вероятностной модели. Поэтому было бы здорово, если бы аналитики явно описывали эту модель, а затем задумывались, подходит ли она под их ситуацию. Выбросами наблюдения становятся только в контексте, и что для одной задачи шум и data contamination, то для другой задачи — норма и совершенно ожидаемое наблюдение.
Больше про работу с выбросами можно узнать вот тут; советую прочитать хотя бы раздел 1.1, он хорошо описывает проблематику.
#statistics
* "Выбросы — это точечки и звездочки на босксплоте."
* "Регрессия / t-тест плохо переваривают выбросы, поэтому их нужно удалять."
* "Если в данных есть выбросы, то нужно использовать непараметрику / ранговые подходы."
И прочее, и прочее.
Редко звучит мысль о том, что не надо просто так удалять выбросы, а стоит задуматься над тем, почему и откуда они взялись в ваших данных, являются ли они органичной частью даты или же это ошибки, хотим ли мы их моделировать, или для нас они экстраординарное явление, которое учитывать в нашей модели мы не хотим. Мысль, что для выбросов стоит предложить вероятностную модель и работать с ними в рамках нее, звучит еще реже.
Теперь слайды.
На Рис. 1 сверху представлена гистограмма некоторой величины X, жирной красной линией отмечено среднее, тоненькими +- SD. Снизу пририсован боксплот: он настолько вырожден, что видно только десять выбросов.
Если мы занимаемся физикой или биомедициной и это наши измерения, то вполне может быть так, что вот эти десять аутлайеров — это какая-то ерунда. Кабель плохо воткнули или при переносе данных кто-то опечатался нулем. В таком случае исключение этих аутлайеров — вполне логичный шаг, который даст нам картинку на Рис. 2.
Посмотрим на это с другой стороны: вы — бузинес, а X — это ваши продажи (отдельные чеки). Действуем так же, как и в прошлый раз, да ведь? Ну хз. На эти ~5% чеков в сумме приходится 60 миллионов выручки, в то время как остальные 200 чеков обеспечивают всего 20 миллионов. Случайность ли это? Или осознанная бизнес-модель, когда реальную выручку вам генерит всего пара крупных контрактов, а все остальное — это скорее маркетинг? Если последнее, то применение ранговых критериев и тем более исключение выбросов сыграет с вами злую шутку.
Наблюдения становятся для нас аутлайерами не потому, что какая-то статистическая процедура пометила их звездочкой. Как мы помним, любой статвывод делается в некоторой вероятностной модели. Поэтому было бы здорово, если бы аналитики явно описывали эту модель, а затем задумывались, подходит ли она под их ситуацию. Выбросами наблюдения становятся только в контексте, и что для одной задачи шум и data contamination, то для другой задачи — норма и совершенно ожидаемое наблюдение.
Больше про работу с выбросами можно узнать вот тут; советую прочитать хотя бы раздел 1.1, он хорошо описывает проблематику.
#statistics
BY душно про дату
Share with your friend now:
tgoop.com/choking_data/37