
tgoop.com/cloud_flight/22
Last Update:
Недавно Ably (SaaS pub/sub) оправдывались в своем блоге за то, что не используют Kubernetes. Статья интересная, много куда попала и вызвала кучу обсуждений. Вот основные тезисы:
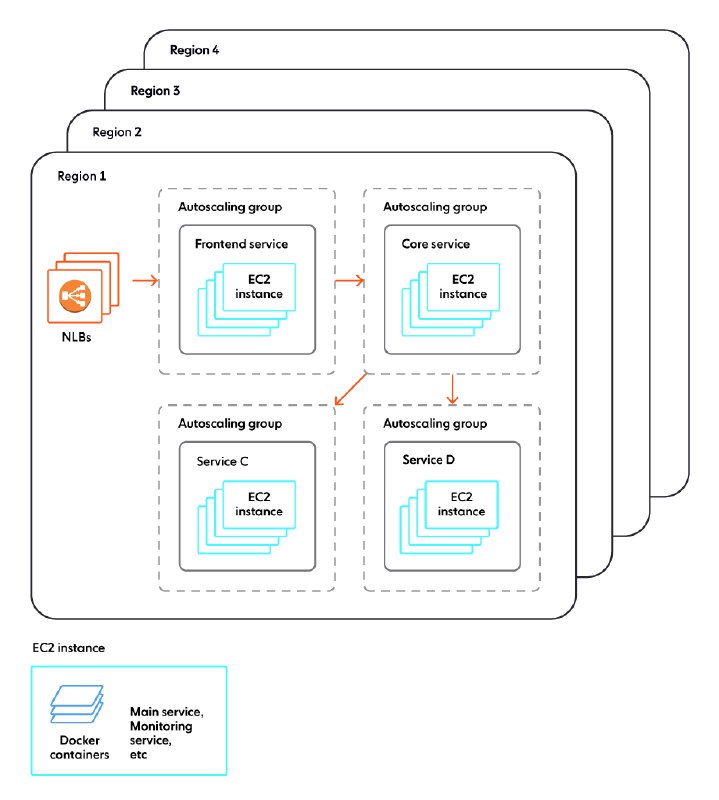
- они используют флот машин с docker контейнерами под управлением AWS Auto Scaling groups;
- каждая группа запускает машины с заданным набором контейнеров;
- масштабирование достигается за счет групп;
- трафик распределяется за счет AWS ELB;
- у k8s большой оверхед и он очень сложный;
- вместо service mesh они используют просто виртуальную сеть AWS.
В целом набор групп + ELB это обычный сценарий разворачивание ландшафта поверх IaaS, и не совсем понятно, в чем тут особенность. Возможно, Ably крутится в среде стартапов, где неиспользование k8s является странным и старомодным, но на деле это вполне обычная архитектура. K8s действительно дает оверхед как по ресурсам, так по биллингу, однако вот что меня удивило:
1. на всех машинах сервисы запускаются в контейнерах, ОС и остальное - одинаковы. Не очень понятно, почему в угоду экономии отказались от K8s, но не отказались от контейнеров. Т.к. для каждой задачи запускается своя группа машин, было бы логичным собрать оптимизированные под эти задачи темплейты, и запускать там приложения без дополнительных уровней абстракции.
2. при старте докер скачивает контейнеры - опять же, почему бы сразу не положить контейнеры в темплейты?
3. автор много раз подчеркивает заоблачную сложность k8s - на деле это обстоит не так, особено если речь про managed k8s. Задача построения ландшафта внутри k8s обычно проще, чем построение того же на основе IaaS решений конкретного облака.
4. service mesh используется не для реализации сети внутри k8s (с чем оркестратор и сам справляется), а для принудительного внедрения сетевых политик в гетерогенную среду (причем это не обязательно k8s, некоторые service mesh, как cilium, работают также поверх ВМ), а также для упрощения внедрения сетевых и инфраструктурых практик (TLS, observability, circuit breaker, всевозможный аудит и т.п.).
Также много интересного было высказано в обсуждениях к статье, например в этом на HN. Если отбросить все комментарии про неработающий сайт (который не выдержал наплыв читателей), то было еще много по существу, например:
- k8s на деле не такой сложный, как описывает автор, комментаторы дали конкретные примеры;
- проблема биллинговой неэффективности не в больших нагрузках, а в неравномерной утилизации ресурсов. Здесь k8s помогает доутилизировать ресурсы ВМ, т.к. более равномерно распределяет нагрузку на ноды;
- запуск множества маленьких ВМ вместо подов k8s менее эффективен, т.к. приходится каждый раз тратить часть ресурсов ВМ на ОС, когда в случае нод k8s более крупного размера эта цена платится один раз на ноду, а контейнер переиспользует ядро для подов;
- вендор лок на AWS может ударить куда сильнее, чем вендор лок на k8s.
В качестве итога: k8s как и любой другой инструмент подходит не каждому, и если внедряемый инструмент не решает никакой проблемы, то он сам становится проблемой. K8s хорошо подходит для достаточно сложных и гетерогенных ландшафтов, и особенно хорош как платформа для реализации крупных инфраструктур с болшим количеством разных сервисов и проектов. Для запуска класической трехзвенки с горизонтальным масштаброванием есть инструменты куда проще - вроде Heroku или GCP App Engine - не стоит их недооценивать. Как и не стоит стесняться запускать свои нагрузки поверх флота ВМ безо всякой сложной оркестрации. Что стоит делать - так это хорошо понимать свой текущий инструментарий, чтобы выжать из него максимум производительности за минимум денег.
BY Витаем в облаках
Share with your friend now:
tgoop.com/cloud_flight/22