tgoop.com/ai_machinelearning_big_data/5998
Last Update:
Stability AI, следуя своему анонсу, выпустила в открытый доступ младшую text-to-image модель семейства Stable diffusion 3.5 - Medium c 2.6 млрд. параметров.
Модель позиционируется в семействе SD 3.5 как решение для работы на потребительском оборудовании.
SD 3.5 Medium способна генерировать изображения с разрешением от 0.25 до 2 мегапикселей, а для запуска с максимальной производительностью ей требуется всего 9.9 Gb VRAM.
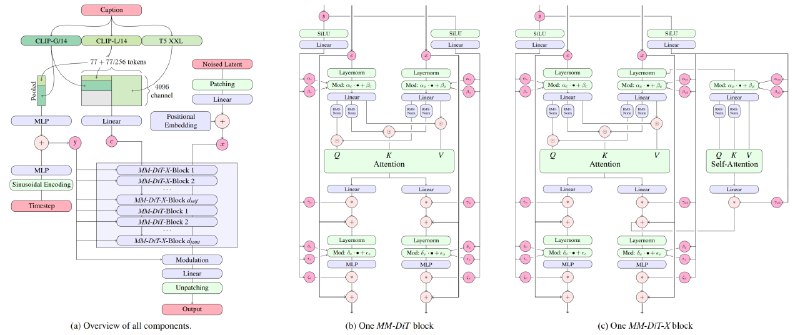
Stable Diffusion 3.5 Medium претерпела ряд изменений в архитектуре (MMDiT-X вместо MMDiT ) и протоколах обучения для корреляции качества с числом параметров, связности и возможности генерации изображений с различным разрешением.
SD 3.5 Medium прошла обучение на разрешениях от 256 до 1440 пикселей.
Текстовые энкодеры не претерпели изменений, остались те же, что и у Stable Diffusion 3.5 Large: OpenCLIP-ViT/G, CLIP-ViT/L и T5-xxl.
Для локального использования модели рекомендуется использовать ComfyUI (базовый воркфлоу) или или Diffusers.
# install Diffusers
pip install -U diffusers
# Inference
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-medium", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
image = pipe(
"A happy woman laying on a grass",
num_inference_steps=28,
guidance_scale=3.5,
).images[0]
image.save("woman.png")
#AI #ML #Diffusion #SD3_5Medium #StabilityAI